 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevCD -- Reversed Conditional Diffusion for Generalized Zero-Shot Learning
Paper and Code
Aug 31, 2024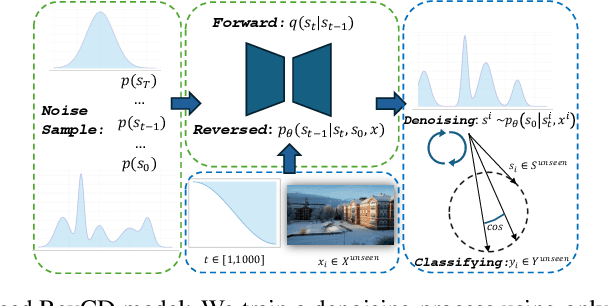

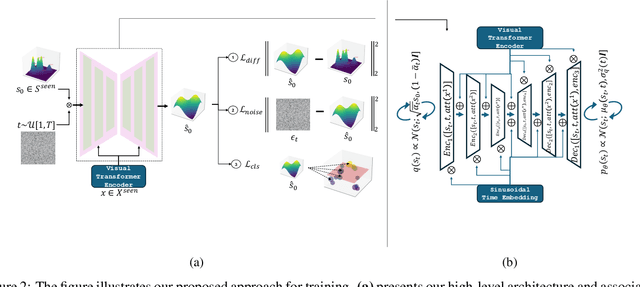

In Generalized Zero-Shot Learning (GZSL), we aim to recognize both seen and unseen categories using a model trained only on seen categories. In computer vision, this translates into a classification problem, where knowledge from seen categories is transferred to unseen categories by exploiting the relationships between visual features and available semantic information, such as text corpora or manual annotations. However, learning this joint distribution is costly and requires one-to-one training with corresponding semantic information. We present a reversed conditional Diffusion-based model (RevCD) that mitigates this issue by generating semantic features synthesized from visual inputs by leveraging Diffusion models' conditional mechanisms. Our RevCD model consists of a cross Hadamard-Addition embedding of a sinusoidal time schedule and a multi-headed visual transformer for attention-guided embeddings. The proposed approach introduces three key innovations. First, we reverse the process of generating semantic space based on visual data, introducing a novel loss function that facilitates more efficient knowledge transfer. Second, we apply Diffusion models to zero-shot learning - a novel approach that exploits their strengths in capturing data complexity. Third, we demonstrate our model's performance through a comprehensive cross-dataset evaluation. The complete code will be available on GitHub.