 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevCD -- Reversed Conditional Diffusion for Generalized Zero-Shot Learning
Aug 31, 2024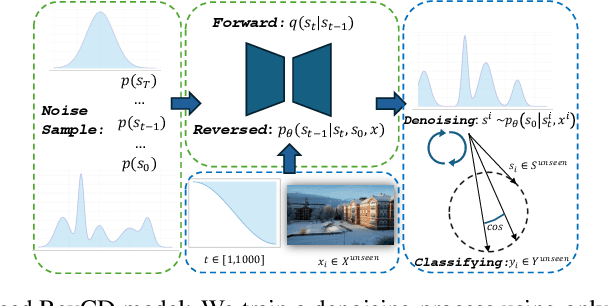

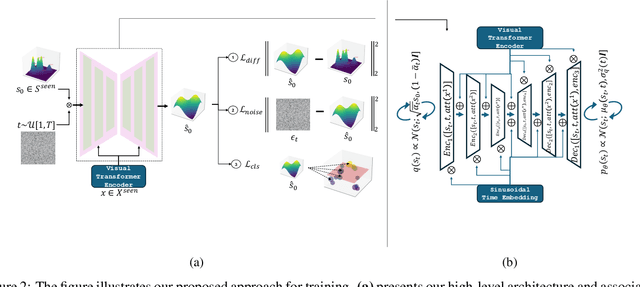

In Generalized Zero-Shot Learning (GZSL), we aim to recognize both seen and unseen categories using a model trained only on seen categories. In computer vision, this translates into a classification problem, where knowledge from seen categories is transferred to unseen categories by exploiting the relationships between visual features and available semantic information, such as text corpora or manual annotations. However, learning this joint distribution is costly and requires one-to-one training with corresponding semantic information. We present a reversed conditional Diffusion-based model (RevCD) that mitigates this issue by generating semantic features synthesized from visual inputs by leveraging Diffusion models' conditional mechanisms. Our RevCD model consists of a cross Hadamard-Addition embedding of a sinusoidal time schedule and a multi-headed visual transformer for attention-guided embeddings. The proposed approach introduces three key innovations. First, we reverse the process of generating semantic space based on visual data, introducing a novel loss function that facilitates more efficient knowledge transfer. Second, we apply Diffusion models to zero-shot learning - a novel approach that exploits their strengths in capturing data complexity. Third, we demonstrate our model's performance through a comprehensive cross-dataset evaluation. The complete code will be available on GitHub.
SEER-ZSL: Semantic Encoder-Enhanced Representations for Generalized Zero-Shot Learning
Dec 20, 2023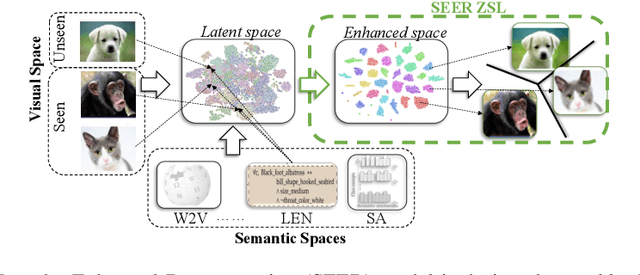
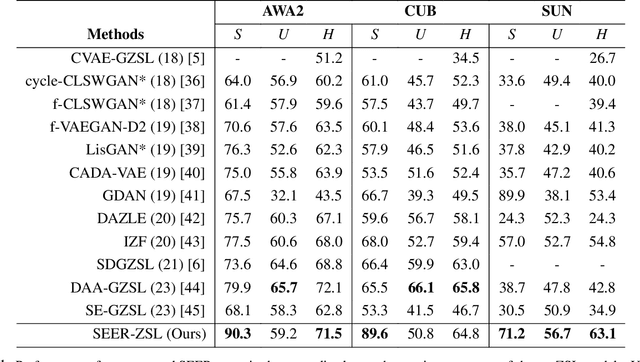
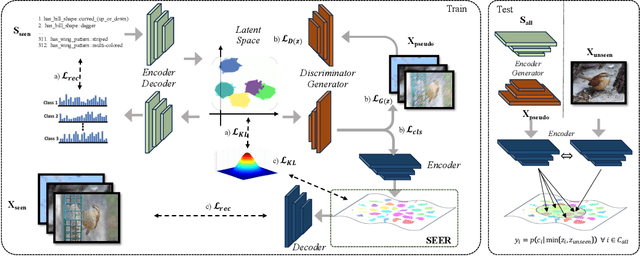
Generalized Zero-Shot Learning (GZSL) recognizes unseen classes by transferring knowledge from the seen classes, depending on the inherent interactions between visual and semantic data. However, the discrepancy between well-prepared training data and unpredictable real-world test scenarios remains a significant challenge. This paper introduces a dual strategy to address the generalization gap. Firstly, we incorporate semantic information through an innovative encoder. This encoder effectively integrates class-specific semantic information by targeting the performance disparity, enhancing the produced features to enrich the semantic space for class-specific attributes. Secondly, we refine our generative capabilities using a novel compositional loss function. This approach generates discriminative classes, effectively classifying both seen and unseen classes. In addition, we extend the exploitation of the learned latent space by utilizing controlled semantic inputs, ensuring the robustness of the model in varying environments. This approach yields a model that outperforms the state-of-the-art models in terms of both generalization and diverse settings, notably without requiring hyperparameter tuning or domain-specific adaptations. We also propose a set of novel evaluation metrics to provide a more detailed assessment of the reliability and reproducibility of the results. The complete code is made available on https://github.com/william-heyden/SEER-ZeroShotLearning/.
An Integral Projection-based Semantic Autoencoder for Zero-Shot Learning
Jun 26, 2023Zero-shot Learning (ZSL) classification categorizes or predicts classes (labels) that are not included in the training set (unseen classes). Recent works proposed different semantic autoencoder (SAE) models where the encoder embeds a visual feature vector space into the semantic space and the decoder reconstructs the original visual feature space. The objective is to learn the embedding by leveraging a source data distribution, which can be applied effectively to a different but related target data distribution. Such embedding-based methods are prone to domain shift problems and are vulnerable to biases. We propose an integral projection-based semantic autoencoder (IP-SAE) where an encoder projects a visual feature space concatenated with the semantic space into a latent representation space. We force the decoder to reconstruct the visual-semantic data space. Due to this constraint, the visual-semantic projection function preserves the discriminatory data included inside the original visual feature space. The enriched projection forces a more precise reconstitution of the visual feature space invariant to the domain manifold. Consequently, the learned projection function is less domain-specific and alleviates the domain shift problem. Our proposed IP-SAE model consolidates a symmetric transformation function for embedding and projection, and thus, it provides transparency for interpreting generative applications in ZSL. Therefore, in addition to outperforming state-of-the-art methods considering four benchmark datasets, our analytical approach allows us to investigate distinct characteristics of generative-based methods in the unique context of zero-shot inference.