 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Context Encoding Module for Semantic Segmentation
Jul 13, 2019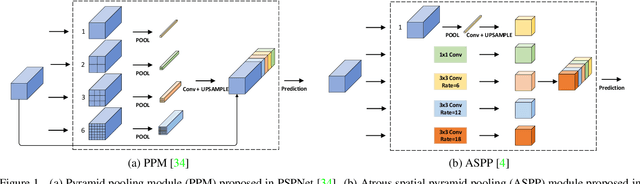
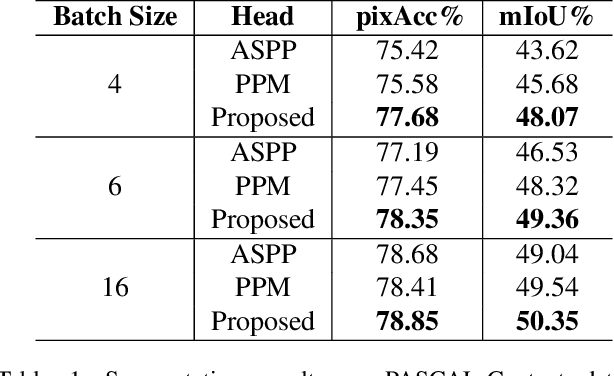
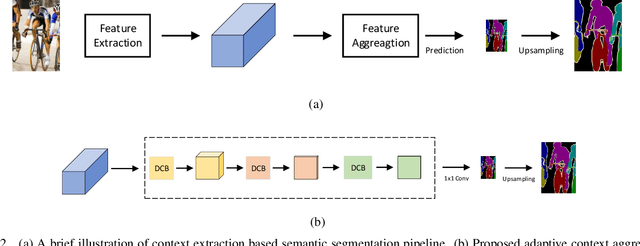

The object sizes in images are diverse, therefore, capturing multiple scale context information is essential for semantic segmentation. Existing context aggregation methods such as pyramid pooling module (PPM) and atrous spatial pyramid pooling (ASPP) design different pooling size or atrous rate, such that multiple scale information is captured. However, the pooling sizes and atrous rates are chosen manually and empirically. In order to capture object context information adaptively, in this paper, we propose an adaptive context encoding (ACE) module based on deformable convolution operation to argument multiple scale information. Our ACE module can be embedded into other Convolutional Neural Networks (CNN) easily for context aggregation. The effectiveness of the proposed module is demonstrated on Pascal-Context and ADE20K datasets. Although our proposed ACE only consists of three deformable convolution blocks, it outperforms PPM and ASPP in terms of mean Intersection of Union (mIoU) on both datasets. All the experiment study confirms that our proposed module is effective as compared to the state-of-the-art methods.
Two-Stage Transfer Learning for Heterogeneous Robot Detection and 3D Joint Position Estimation in a 2D Camera Image using CNN
Feb 15, 2019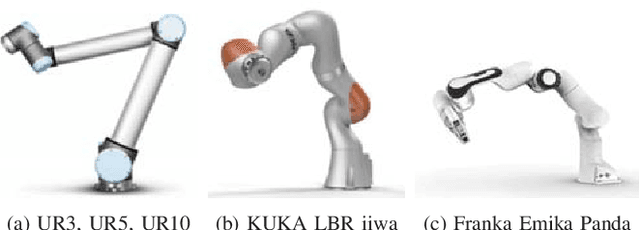


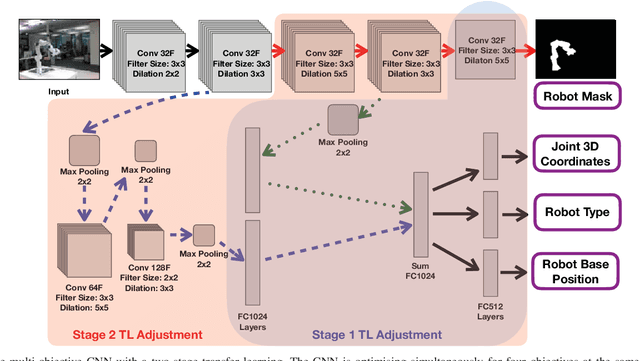
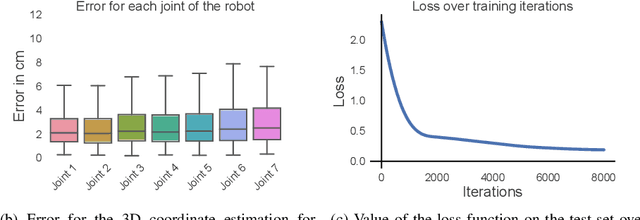
Collaborative robots are becoming more common on factory floors as well as regular environments, however, their safety still is not a fully solved issue. Collision detection does not always perform as expected and collision avoidance is still an active research area. Collision avoidance works well for fixed robot-camera setups, however, if they are shifted around, Eye-to-Hand calibration becomes invalid making it difficult to accurately run many of the existing collision avoidance algorithms. We approach the problem by presenting a stand-alone system capable of detecting the robot and estimating its position, including individual joints, by using a simple 2D colour image as an input, where no Eye-to-Hand calibration is needed. As an extension of previous work, a two-stage transfer learning approach is used to re-train a multi-objective convolutional neural network (CNN) to allow it to be used with heterogeneous robot arms. Our method is capable of detecting the robot in real-time and new robot types can be added by having significantly smaller training datasets compared to the requirements of a fully trained network. We present data collection approach, the structure of the multi-objective CNN, the two-stage transfer learning training and test results by using real robots from Universal Robots, Kuka, and Franka Emika. Eventually, we analyse possible application areas of our method together with the possible improvements.
Transfer Learning for Unseen Robot Detection and Joint Estimation on a Multi-Objective Convolutional Neural Network
Jun 11, 2018

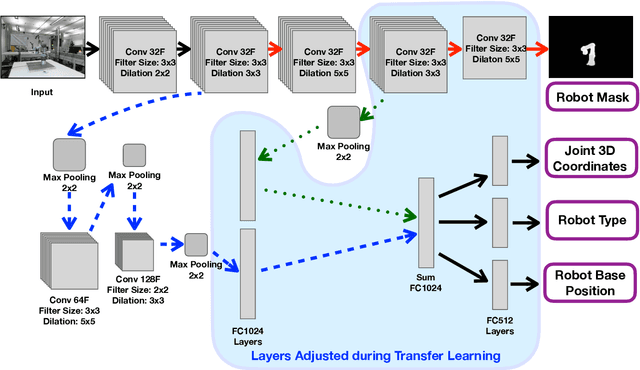
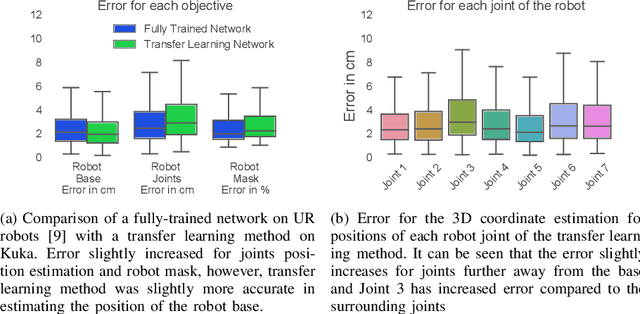
A significant problem of using deep learning techniques is the limited amount of data available for training. There are some datasets available for the popular problems like item recognition and classification or self-driving cars, however, it is very limited for the industrial robotics field. In previous work, we have trained a multi-objective Convolutional Neural Network (CNN) to identify the robot body in the image and estimate 3D positions of the joints by using just a 2D image, but it was limited to a range of robots produced by Universal Robots (UR). In this work, we extend our method to work with a new robot arm - Kuka LBR iiwa, which has a significantly different appearance and an additional joint. However, instead of collecting large datasets once again, we collect a number of smaller datasets containing a few hundred frames each and use transfer learning techniques on the CNN trained on UR robots to adapt it to a new robot having different shapes and visual features. We have proven that transfer learning is not only applicable in this field, but it requires smaller well-prepared training datasets, trains significantly faster and reaches similar accuracy compared to the original method, even improving it on some aspects.
Robot Localisation and 3D Position Estimation Using a Free-Moving Camera and Cascaded Convolutional Neural Networks
May 30, 2018



Many works in collaborative robotics and human-robot interaction focuses on identifying and predicting human behaviour while considering the information about the robot itself as given. This can be the case when sensors and the robot are calibrated in relation to each other and often the reconfiguration of the system is not possible, or extra manual work is required. We present a deep learning based approach to remove the constraint of having the need for the robot and the vision sensor to be fixed and calibrated in relation to each other. The system learns the visual cues of the robot body and is able to localise it, as well as estimate the position of robot joints in 3D space by just using a 2D color image. The method uses a cascaded convolutional neural network, and we present the structure of the network, describe our own collected dataset, explain the network training and achieved results. A fully trained system shows promising results in providing an accurate mask of where the robot is located and a good estimate of its joints positions in 3D. The accuracy is not good enough for visual servoing applications yet, however, it can be sufficient for general safety and some collaborative tasks not requiring very high precision. The main benefit of our method is the possibility of the vision sensor to move freely. This allows it to be mounted on moving objects, for example, a body of the person or a mobile robot working in the same environment as the robots are operating in.
Multi-Objective Convolutional Neural Networks for Robot Localisation and 3D Position Estimation in 2D Camera Images
May 30, 2018

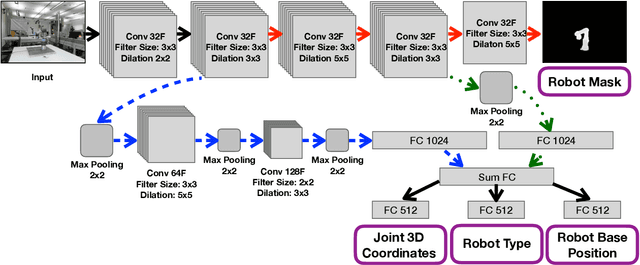
The field of collaborative robotics and human-robot interaction often focuses on the prediction of human behaviour, while assuming the information about the robot setup and configuration being known. This is often the case with fixed setups, which have all the sensors fixed and calibrated in relation to the rest of the system. However, it becomes a limiting factor when the system needs to be reconfigured or moved. We present a deep learning approach, which aims to solve this issue. Our method learns to identify and precisely localise the robot in 2D camera images, so having a fixed setup is no longer a requirement and a camera can be moved. In addition, our approach identifies the robot type and estimates the 3D position of the robot base in the camera image as well as 3D positions of each of the robot joints. Learning is done by using a multi-objective convolutional neural network with four previously mentioned objectives simultaneously using a combined loss function. The multi-objective approach makes the system more flexible and efficient by reusing some of the same features and diversifying for each objective in lower layers. A fully trained system shows promising results in providing an accurate mask of where the robot is located and an estimate of its base and joint positions in 3D. We compare the results to our previous approach of using cascaded convolutional neural networks.
Multi 3D Camera Mapping for Predictive and Reflexive Robot Manipulator Trajectory Estimation
Oct 12, 2016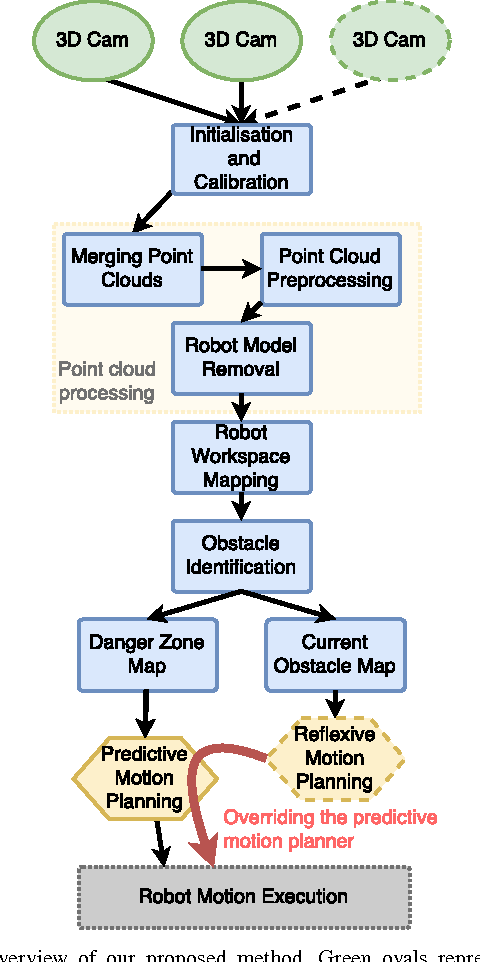


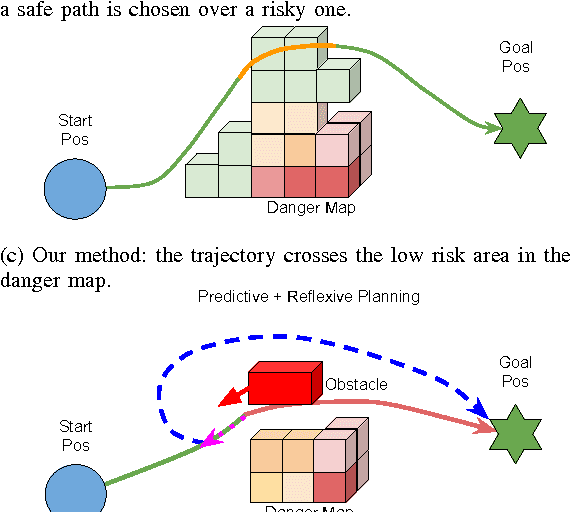
With advancing technologies, robotic manipulators and visual environment sensors are becoming cheaper and more widespread. However, robot control can be still a limiting factor for better adaptation of these technologies. Robotic manipulators are performing very well in structured workspaces, but do not adapt well to unexpected changes, like people entering the workspace. We present a method combining 3D Camera based workspace mapping, and a predictive and reflexive robot manipulator trajectory estimation to allow more efficient and safer operation in dynamic workspaces. In experiments on a real UR5 robot our method has proven to provide shorter and smoother trajectories compared to a reactive trajectory planner in the same conditions. Furthermore, the robot has successfully avoided any contact by initialising the reflexive movement even when an obstacle got unexpectedly close to the robot. The main goal of our work is to make the operation more flexible in unstructured dynamic workspaces and not just avoid obstacles, but also adapt when performing collaborative tasks with humans in the near future.
Automatic Calibration of a Robot Manipulator and Multi 3D Camera System
Oct 12, 2016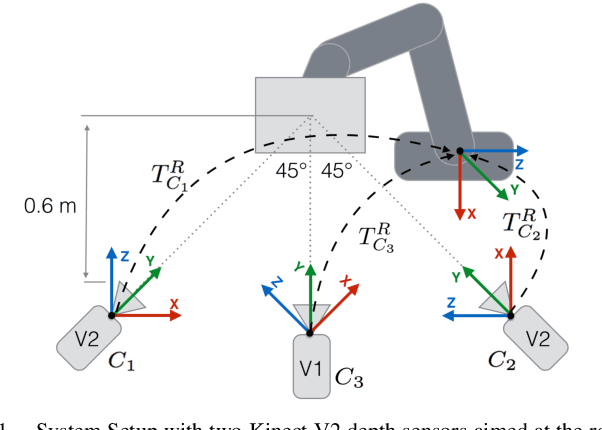


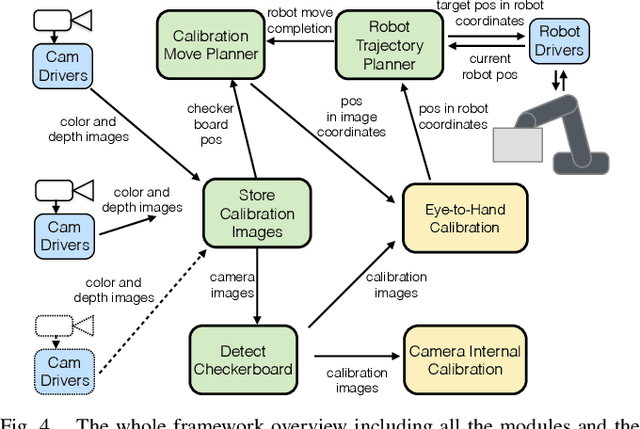
With 3D sensing becoming cheaper, environment-aware and visually-guided robot arms capable of safely working in collaboration with humans will become common. However, a reliable calibration is needed, both for camera internal calibration, as well as Eye-to-Hand calibration, to make sure the whole system functions correctly. We present a framework, using a novel combination of well proven methods, allowing a quick automatic calibration for the integration of systems consisting of the robot and a varying number of 3D cameras by using a standard checkerboard calibration grid. Our approach allows a quick camera-to-robot recalibration after any changes to the setup, for example when cameras or robot have been repositioned. Modular design of the system ensures flexibility regarding a number of sensors used as well as different hardware choices. The framework has been proven to work by practical experiments to analyze the quality of the calibration versus the number of positions of the checkerboard used for each of the calibration procedures.