 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Diffusion-LM: Apply Diffusion Model on Image Captioning
Paper and Code
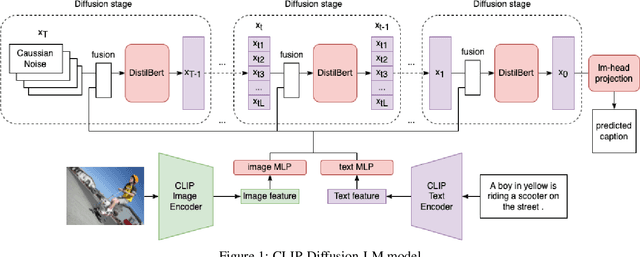
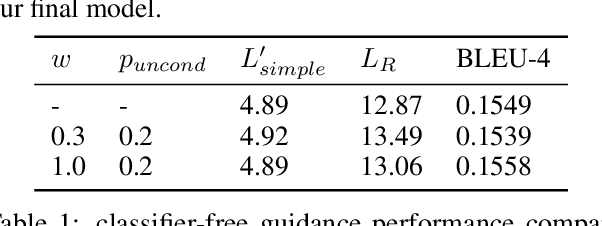

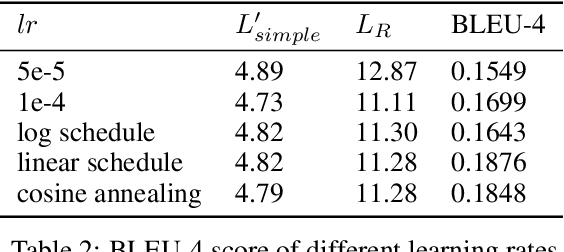
Image captioning task has been extensively researched by previous work. However, limited experiments focus on generating captions based on non-autoregressive text decoder. Inspired by the recent success of the denoising diffusion model on image synthesis tasks, we apply denoising diffusion probabilistic models to text generation in image captioning tasks. We show that our CLIP-Diffusion-LM is capable of generating image captions using significantly fewer inference steps than autoregressive models. On the Flickr8k dataset, the model achieves 0.1876 BLEU-4 score. By training on the combined Flickr8k and Flickr30k dataset, our model achieves 0.2470 BLEU-4 score. Our code is available at https://github.com/xu-shitong/diffusion-image-captioning.