 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCoRL: Continual Reinforcement Learning via Policy Distillation
Jul 11, 2019
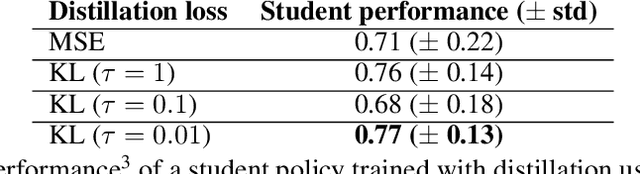
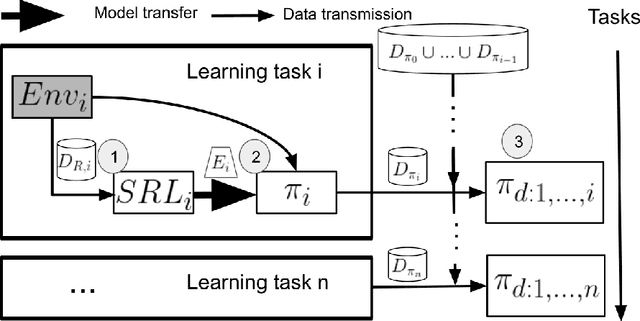
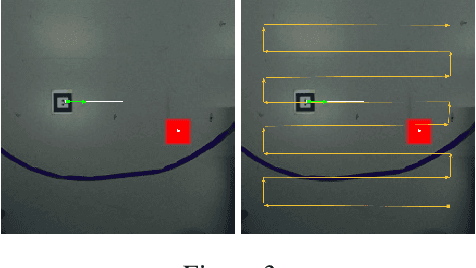
In multi-task reinforcement learning there are two main challenges: at training time, the ability to learn different policies with a single model; at test time, inferring which of those policies applying without an external signal. In the case of continual reinforcement learning a third challenge arises: learning tasks sequentially without forgetting the previous ones. In this paper, we tackle these challenges by proposing DisCoRL, an approach combining state representation learning and policy distillation. We experiment on a sequence of three simulated 2D navigation tasks with a 3 wheel omni-directional robot. Moreover, we tested our approach's robustness by transferring the final policy into a real life setting. The policy can solve all tasks and automatically infer which one to run.
Continual Reinforcement Learning deployed in Real-life using Policy Distillation and Sim2Real Transfer
Jun 11, 2019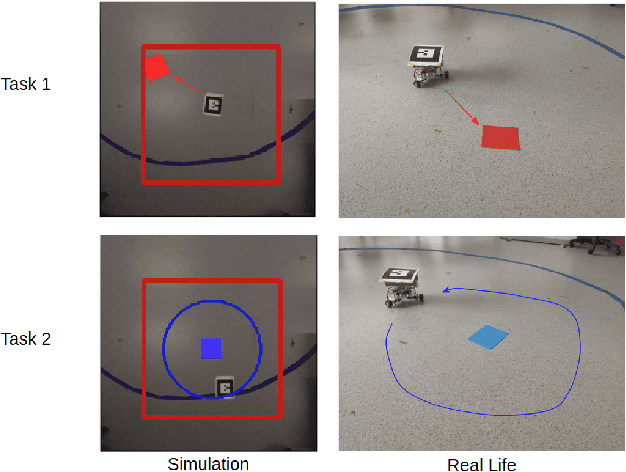
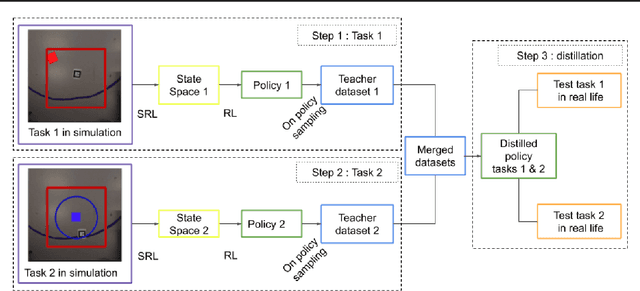
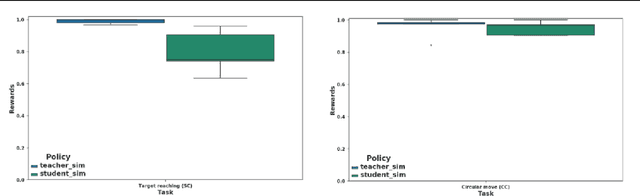
We focus on the problem of teaching a robot to solve tasks presented sequentially, i.e., in a continual learning scenario. The robot should be able to solve all tasks it has encountered, without forgetting past tasks. We provide preliminary work on applying Reinforcement Learning to such setting, on 2D navigation tasks for a 3 wheel omni-directional robot. Our approach takes advantage of state representation learning and policy distillation. Policies are trained using learned features as input, rather than raw observations, allowing better sample efficiency. Policy distillation is used to combine multiple policies into a single one that solves all encountered tasks.
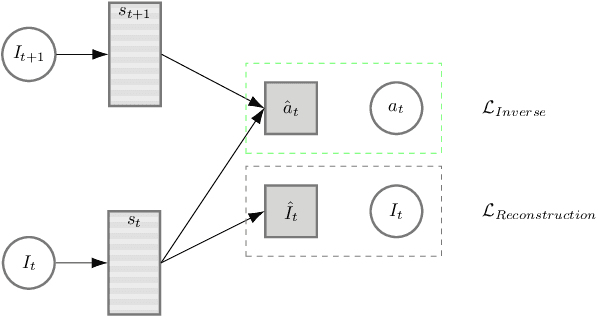
Decoupling feature extraction from policy learning: assessing benefits of state representation learning in goal based robotics
Feb 03, 2019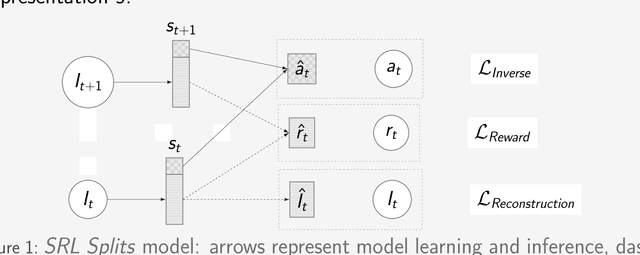
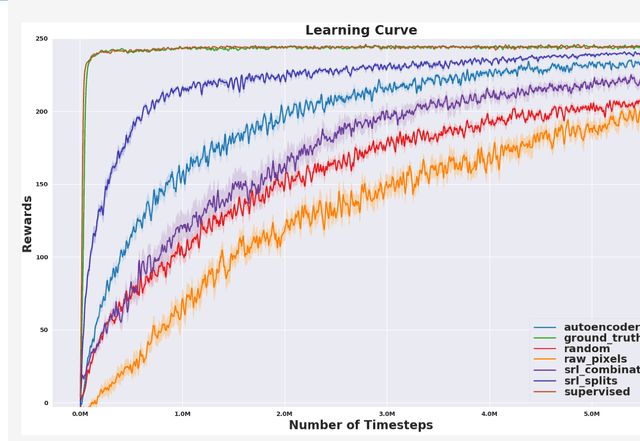
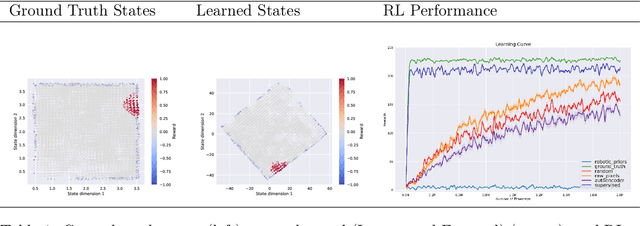
Scaling end-to-end reinforcement learning to control real robots from vision presents a series of challenges, in particular in terms of sample efficiency. Against end-to-end learning, state representation learning can help learn a compact, efficient and relevant representation of states that speeds up policy learning, reducing the number of samples needed, and that is easier to interpret. We evaluate several state representation learning methods on goal based robotics tasks and propose a new unsupervised model that stacks representations and combines strengths of several of these approaches. This method encodes all the relevant features, performs on par or better than end-to-end learning, and is robust to hyper-parameters change.
S-RL Toolbox: Environments, Datasets and Evaluation Metrics for State Representation Learning
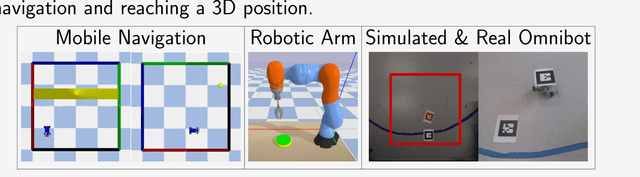
Oct 10, 2018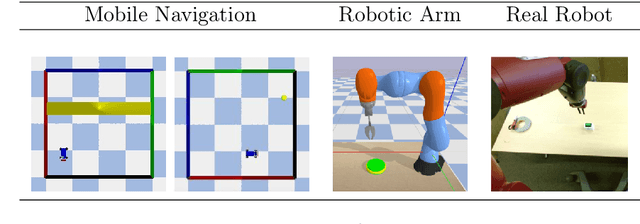
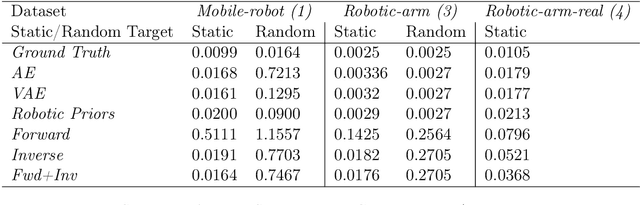
State representation learning aims at learning compact representations from raw observations in robotics and control applications. Approaches used for this objective are auto-encoders, learning forward models, inverse dynamics or learning using generic priors on the state characteristics. However, the diversity in applications and methods makes the field lack standard evaluation datasets, metrics and tasks. This paper provides a set of environments, data generators, robotic control tasks, metrics and tools to facilitate iterative state representation learning and evaluation in reinforcement learning settings.