 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Risk-sensitive RL with Partial Observability to Enhance Performance in Human-Robot Teaming
Feb 08, 2024



The integration of physiological computing into mixed-initiative human-robot interaction systems offers valuable advantages in autonomous task allocation by incorporating real-time features as human state observations into the decision-making system. This approach may alleviate the cognitive load on human operators by intelligently allocating mission tasks between agents. Nevertheless, accommodating a diverse pool of human participants with varying physiological and behavioral measurements presents a substantial challenge. To address this, resorting to a probabilistic framework becomes necessary, given the inherent uncertainty and partial observability on the human's state. Recent research suggests to learn a Partially Observable Markov Decision Process (POMDP) model from a data set of previously collected experiences that can be solved using Offline Reinforcement Learning (ORL) methods. In the present work, we not only highlight the potential of partially observable representations and physiological measurements to improve human operator state estimation and performance, but also enhance the overall mission effectiveness of a human-robot team. Importantly, as the fixed data set may not contain enough information to fully represent complex stochastic processes, we propose a method to incorporate model uncertainty, thus enabling risk-sensitive sequential decision-making. Experiments were conducted with a group of twenty-six human participants within a simulated robot teleoperation environment, yielding empirical evidence of the method's efficacy. The obtained adaptive task allocation policy led to statistically significant higher scores than the one that was used to collect the data set, allowing for generalization across diverse participants also taking into account risk-sensitive metrics.
HyPE: Attention with Hyperbolic Biases for Relative Positional Encoding
Oct 30, 2023In Transformer-based architectures, the attention mechanism is inherently permutation-invariant with respect to the input sequence's tokens. To impose sequential order, token positions are typically encoded using a scheme with either fixed or learnable parameters. We introduce Hyperbolic Positional Encoding (HyPE), a novel method that utilizes hyperbolic functions' properties to encode tokens' relative positions. This approach biases the attention mechanism without the necessity of storing the $O(L^2)$ values of the mask, with $L$ being the length of the input sequence. HyPE leverages preliminary concatenation operations and matrix multiplications, facilitating the encoding of relative distances indirectly incorporating biases into the softmax computation. This design ensures compatibility with FlashAttention-2 and supports the gradient backpropagation for any potential learnable parameters within the encoding. We analytically demonstrate that, by careful hyperparameter selection, HyPE can approximate the attention bias of ALiBi, thereby offering promising generalization capabilities for contexts extending beyond the lengths encountered during pretraining. The experimental evaluation of HyPE is proposed as a direction for future research.
Towards a more efficient computation of individual attribute and policy contribution for post-hoc explanation of cooperative multi-agent systems using Myerson values
Dec 06, 2022A quantitative assessment of the global importance of an agent in a team is as valuable as gold for strategists, decision-makers, and sports coaches. Yet, retrieving this information is not trivial since in a cooperative task it is hard to isolate the performance of an individual from the one of the whole team. Moreover, it is not always clear the relationship between the role of an agent and his personal attributes. In this work we conceive an application of the Shapley analysis for studying the contribution of both agent policies and attributes, putting them on equal footing. Since the computational complexity is NP-hard and scales exponentially with the number of participants in a transferable utility coalitional game, we resort to exploiting a-priori knowledge about the rules of the game to constrain the relations between the participants over a graph. We hence propose a method to determine a Hierarchical Knowledge Graph of agents' policies and features in a Multi-Agent System. Assuming a simulator of the system is available, the graph structure allows to exploit dynamic programming to assess the importances in a much faster way. We test the proposed approach in a proof-of-case environment deploying both hardcoded policies and policies obtained via Deep Reinforcement Learning. The proposed paradigm is less computationally demanding than trivially computing the Shapley values and provides great insight not only into the importance of an agent in a team but also into the attributes needed to deploy the policy at its best.
Exploiting Expert-guided Symmetry Detection in Markov Decision Processes
Dec 18, 2021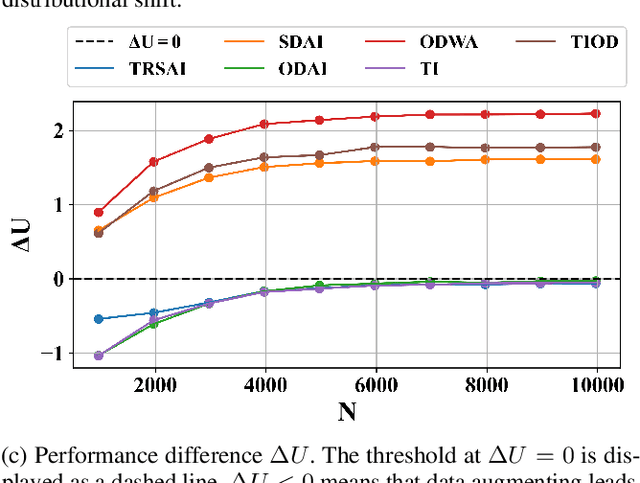

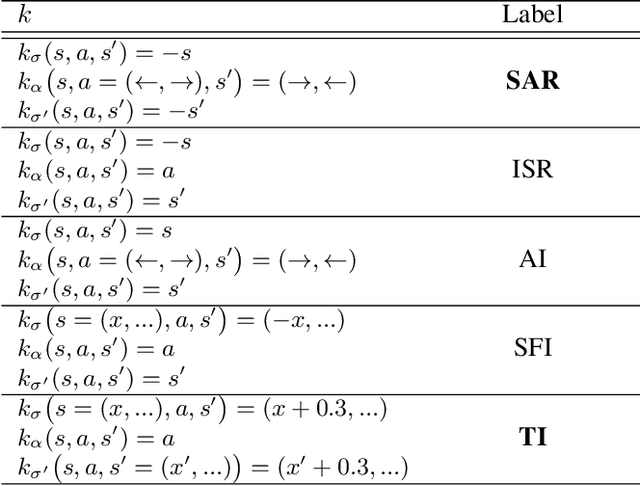
Offline estimation of the dynamical model of a Markov Decision Process (MDP) is a non-trivial task that greatly depends on the data available to the learning phase. Sometimes the dynamics of the model is invariant with respect to some transformations of the current state and action. Recent works showed that an expert-guided pipeline relying on Density Estimation methods as Deep Neural Network based Normalizing Flows effectively detects this structure in deterministic environments, both categorical and continuous-valued. The acquired knowledge can be exploited to augment the original data set, leading eventually to a reduction in the distributional shift between the true and the learnt model. In this work we extend the paradigm to also tackle non deterministic MDPs, in particular 1) we propose a detection threshold in categorical environments based on statistical distances, 2) we introduce a benchmark of the distributional shift in continuous environments based on the Wilcoxon signed-rank statistical test and 3) we show that the former results lead to a performance improvement when solving the learnt MDP and then applying the optimal policy in the real environment.
Expert-Guided Symmetry Detection in Markov Decision Processes
Nov 19, 2021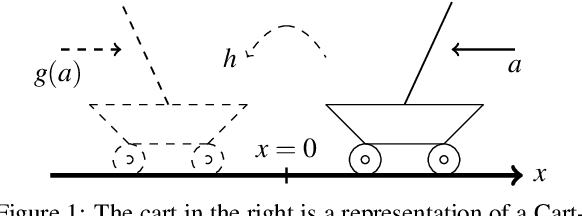
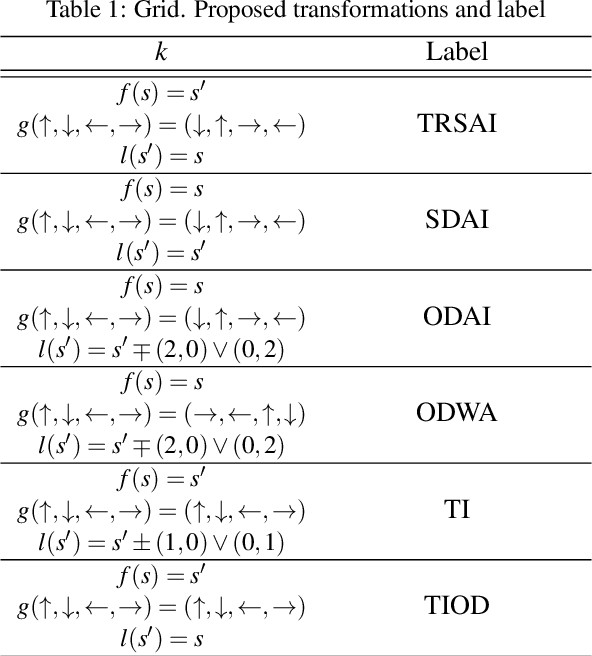
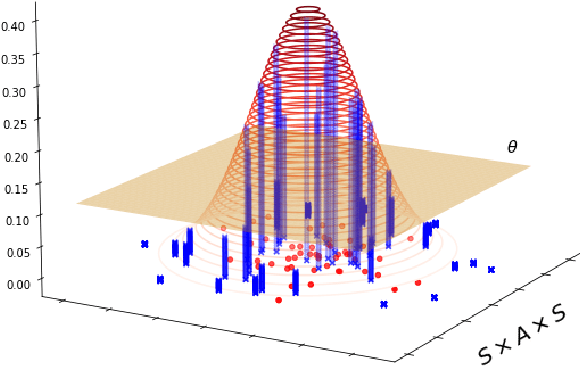

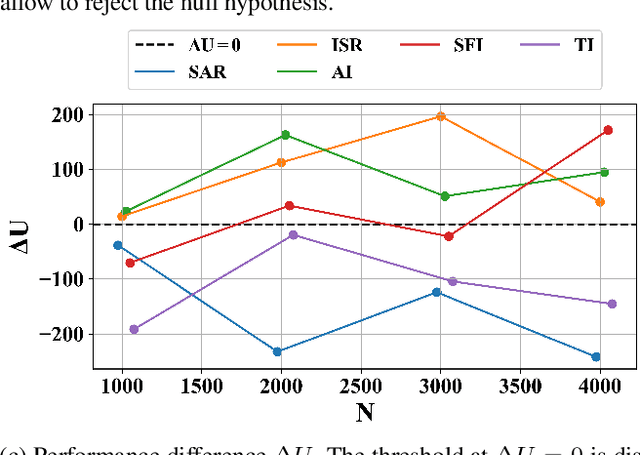
Learning a Markov Decision Process (MDP) from a fixed batch of trajectories is a non-trivial task whose outcome's quality depends on both the amount and the diversity of the sampled regions of the state-action space. Yet, many MDPs are endowed with invariant reward and transition functions with respect to some transformations of the current state and action. Being able to detect and exploit these structures could benefit not only the learning of the MDP but also the computation of its subsequent optimal control policy. In this work we propose a paradigm, based on Density Estimation methods, that aims to detect the presence of some already supposed transformations of the state-action space for which the MDP dynamics is invariant. We tested the proposed approach in a discrete toroidal grid environment and in two notorious environments of OpenAI's Gym Learning Suite. The results demonstrate that the model distributional shift is reduced when the dataset is augmented with the data obtained by using the detected symmetries, allowing for a more thorough and data-efficient learning of the transition functions.
Exploitation vs Caution: Risk-sensitive Policies for Offline Learning
May 27, 2021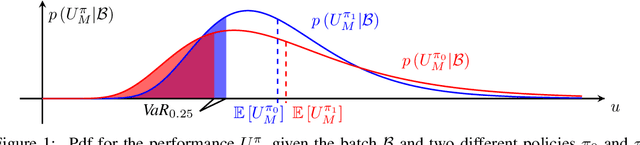
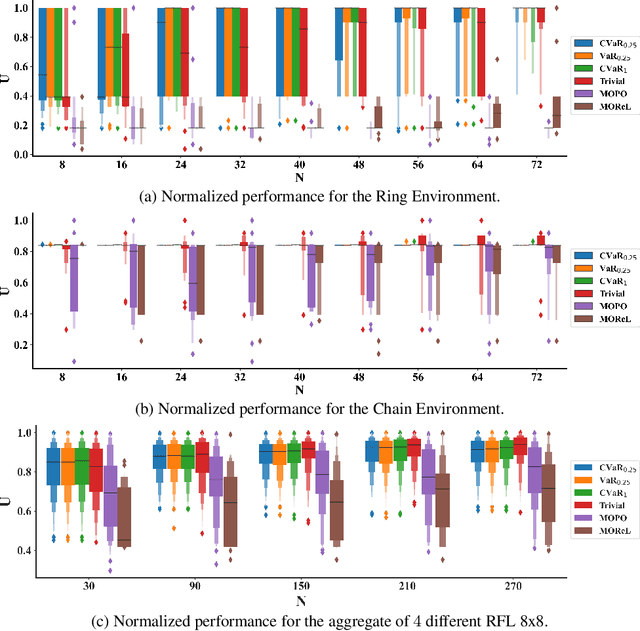
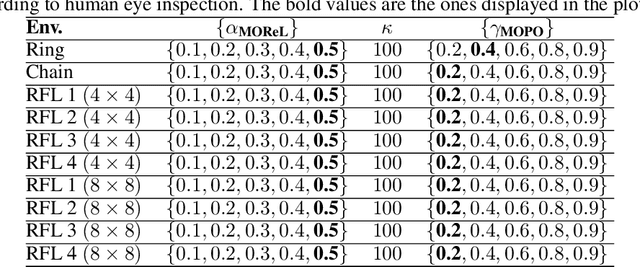

Offline model learning for planning is a branch of machine learning that trains agents to perform actions in an unknown environment using a fixed batch of previously collected experiences. The limited size of the data set hinders the estimate of the Value function of the relative Markov Decision Process (MDP), bounding the performance of the obtained policy in the real world. In this context, recent works showed that planning with a discount factor lower than the one used during the evaluation phase yields more performing policies. However, the optimal discount factor is finally chosen by cross-validation. Our aim is to show that looking for a sub-optimal solution of a Bayesian MDP might lead to better performances with respect to the current baselines that work in the offline setting. Hence, we propose Exploitation vs Caution (EvC), an algorithm that automatically selects the policy that solves a Risk-sensitive Bayesian MDP in a set of policies obtained by solving several MDPs characterized by different discount factors and transition dynamics. On one hand, the Bayesian formalism elegantly includes model uncertainty and on another hand the introduction of a risk-sensitive utility function guarantees robustness. We evaluated the proposed approach in different discrete simple environments offering a fair variety of MDP classes. We also compared the obtained results with state-of-the-art offline learning for planning baselines such as MOPO and MOReL. In the tested scenarios EvC is more robust than the said approaches suggesting that sub-optimally solving an Offline Risk-sensitive Bayesian MDP (ORBMDP) could define a sound framework for planning under model uncertainty.
Offline Learning for Planning: A Summary
Oct 05, 2020

The training of autonomous agents often requires expensive and unsafe trial-and-error interactions with the environment. Nowadays several data sets containing recorded experiences of intelligent agents performing various tasks, spanning from the control of unmanned vehicles to human-robot interaction and medical applications are accessible on the internet. With the intention of limiting the costs of the learning procedure it is convenient to exploit the information that is already available rather than collecting new data. Nevertheless, the incapability to augment the batch can lead the autonomous agents to develop far from optimal behaviours when the sampled experiences do not allow for a good estimate of the true distribution of the environment. Offline learning is the area of machine learning concerned with efficiently obtaining an optimal policy with a batch of previously collected experiences without further interaction with the environment. In this paper we adumbrate the ideas motivating the development of the state-of-the-art offline learning baselines. The listed methods consist in the introduction of epistemic uncertainty dependent constraints during the classical resolution of a Markov Decision Process, with and without function approximators, that aims to alleviate the bad effects of the distributional mismatch between the available samples and real world. We provide comments on the practical utility of the theoretical bounds that justify the application of these algorithms and suggest the utilization of Generative Adversarial Networks to estimate the distributional shift that affects all of the proposed model-free and model-based approaches.