 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert-Guided Symmetry Detection in Markov Decision Processes
Paper and Code
Nov 19, 2021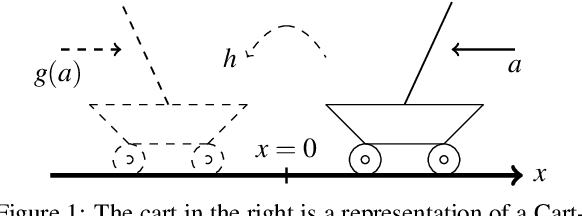
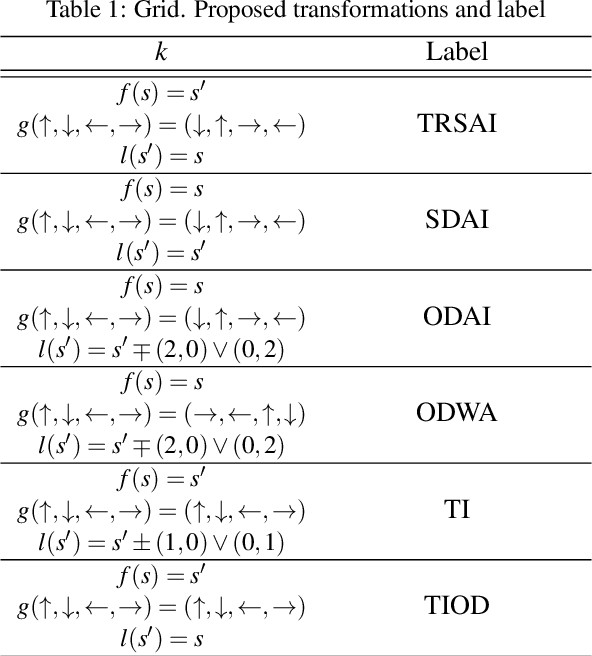
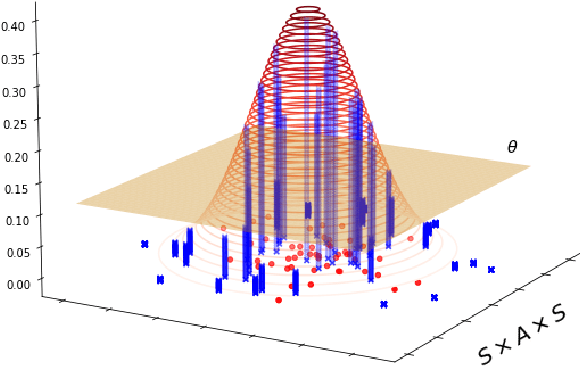

Learning a Markov Decision Process (MDP) from a fixed batch of trajectories is a non-trivial task whose outcome's quality depends on both the amount and the diversity of the sampled regions of the state-action space. Yet, many MDPs are endowed with invariant reward and transition functions with respect to some transformations of the current state and action. Being able to detect and exploit these structures could benefit not only the learning of the MDP but also the computation of its subsequent optimal control policy. In this work we propose a paradigm, based on Density Estimation methods, that aims to detect the presence of some already supposed transformations of the state-action space for which the MDP dynamics is invariant. We tested the proposed approach in a discrete toroidal grid environment and in two notorious environments of OpenAI's Gym Learning Suite. The results demonstrate that the model distributional shift is reduced when the dataset is augmented with the data obtained by using the detected symmetries, allowing for a more thorough and data-efficient learning of the transition functions.