 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Risk-sensitive RL with Partial Observability to Enhance Performance in Human-Robot Teaming
Feb 08, 2024



The integration of physiological computing into mixed-initiative human-robot interaction systems offers valuable advantages in autonomous task allocation by incorporating real-time features as human state observations into the decision-making system. This approach may alleviate the cognitive load on human operators by intelligently allocating mission tasks between agents. Nevertheless, accommodating a diverse pool of human participants with varying physiological and behavioral measurements presents a substantial challenge. To address this, resorting to a probabilistic framework becomes necessary, given the inherent uncertainty and partial observability on the human's state. Recent research suggests to learn a Partially Observable Markov Decision Process (POMDP) model from a data set of previously collected experiences that can be solved using Offline Reinforcement Learning (ORL) methods. In the present work, we not only highlight the potential of partially observable representations and physiological measurements to improve human operator state estimation and performance, but also enhance the overall mission effectiveness of a human-robot team. Importantly, as the fixed data set may not contain enough information to fully represent complex stochastic processes, we propose a method to incorporate model uncertainty, thus enabling risk-sensitive sequential decision-making. Experiments were conducted with a group of twenty-six human participants within a simulated robot teleoperation environment, yielding empirical evidence of the method's efficacy. The obtained adaptive task allocation policy led to statistically significant higher scores than the one that was used to collect the data set, allowing for generalization across diverse participants also taking into account risk-sensitive metrics.
Exploiting Expert-guided Symmetry Detection in Markov Decision Processes
Dec 18, 2021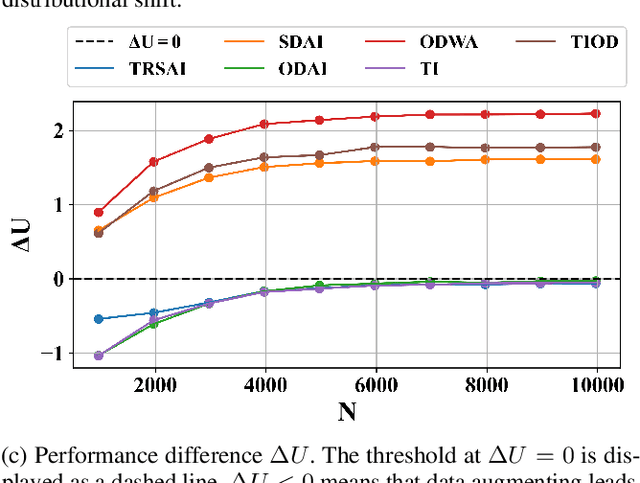

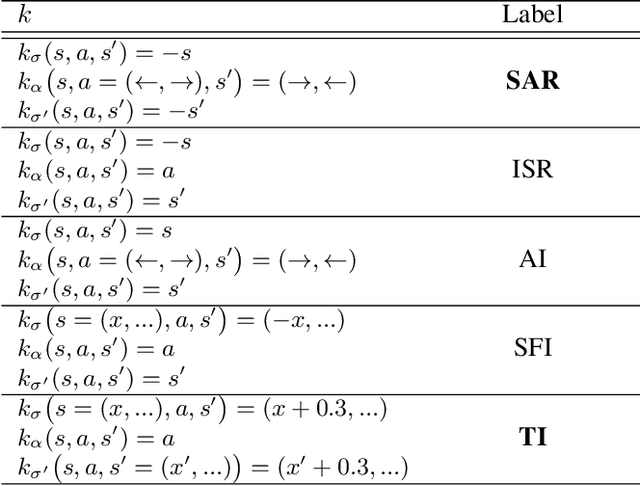
Offline estimation of the dynamical model of a Markov Decision Process (MDP) is a non-trivial task that greatly depends on the data available to the learning phase. Sometimes the dynamics of the model is invariant with respect to some transformations of the current state and action. Recent works showed that an expert-guided pipeline relying on Density Estimation methods as Deep Neural Network based Normalizing Flows effectively detects this structure in deterministic environments, both categorical and continuous-valued. The acquired knowledge can be exploited to augment the original data set, leading eventually to a reduction in the distributional shift between the true and the learnt model. In this work we extend the paradigm to also tackle non deterministic MDPs, in particular 1) we propose a detection threshold in categorical environments based on statistical distances, 2) we introduce a benchmark of the distributional shift in continuous environments based on the Wilcoxon signed-rank statistical test and 3) we show that the former results lead to a performance improvement when solving the learnt MDP and then applying the optimal policy in the real environment.
Expert-Guided Symmetry Detection in Markov Decision Processes
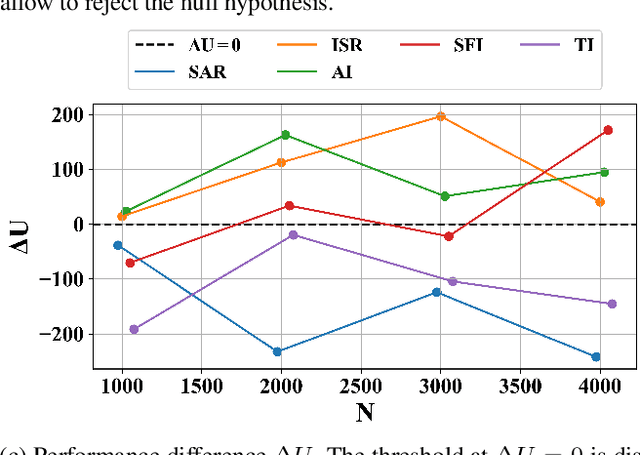
Nov 19, 2021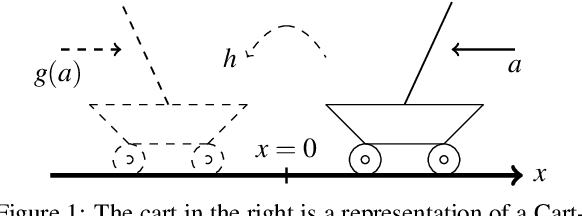
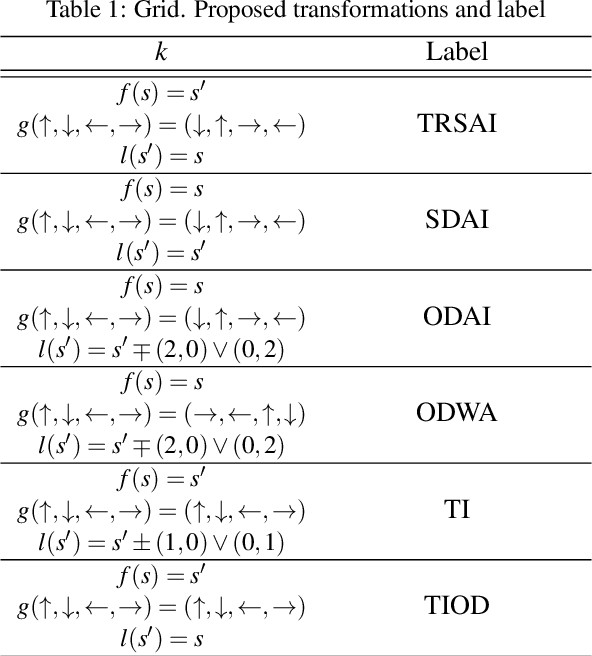

Learning a Markov Decision Process (MDP) from a fixed batch of trajectories is a non-trivial task whose outcome's quality depends on both the amount and the diversity of the sampled regions of the state-action space. Yet, many MDPs are endowed with invariant reward and transition functions with respect to some transformations of the current state and action. Being able to detect and exploit these structures could benefit not only the learning of the MDP but also the computation of its subsequent optimal control policy. In this work we propose a paradigm, based on Density Estimation methods, that aims to detect the presence of some already supposed transformations of the state-action space for which the MDP dynamics is invariant. We tested the proposed approach in a discrete toroidal grid environment and in two notorious environments of OpenAI's Gym Learning Suite. The results demonstrate that the model distributional shift is reduced when the dataset is augmented with the data obtained by using the detected symmetries, allowing for a more thorough and data-efficient learning of the transition functions.