 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploitation vs Caution: Risk-sensitive Policies for Offline Learning
May 27, 2021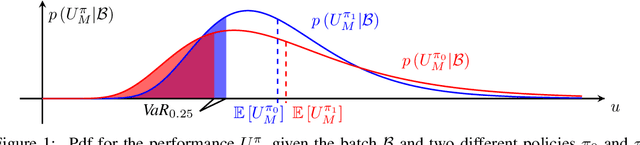
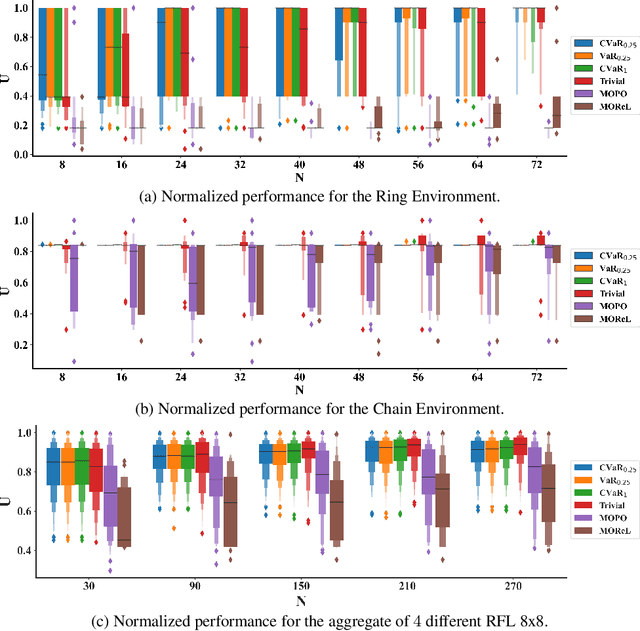
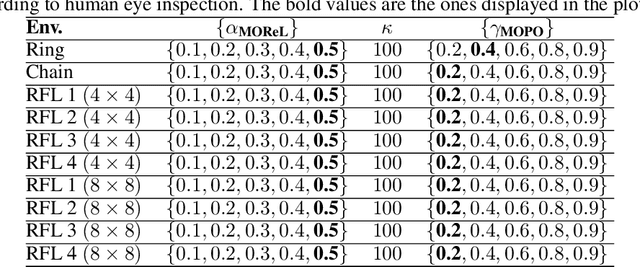

Offline model learning for planning is a branch of machine learning that trains agents to perform actions in an unknown environment using a fixed batch of previously collected experiences. The limited size of the data set hinders the estimate of the Value function of the relative Markov Decision Process (MDP), bounding the performance of the obtained policy in the real world. In this context, recent works showed that planning with a discount factor lower than the one used during the evaluation phase yields more performing policies. However, the optimal discount factor is finally chosen by cross-validation. Our aim is to show that looking for a sub-optimal solution of a Bayesian MDP might lead to better performances with respect to the current baselines that work in the offline setting. Hence, we propose Exploitation vs Caution (EvC), an algorithm that automatically selects the policy that solves a Risk-sensitive Bayesian MDP in a set of policies obtained by solving several MDPs characterized by different discount factors and transition dynamics. On one hand, the Bayesian formalism elegantly includes model uncertainty and on another hand the introduction of a risk-sensitive utility function guarantees robustness. We evaluated the proposed approach in different discrete simple environments offering a fair variety of MDP classes. We also compared the obtained results with state-of-the-art offline learning for planning baselines such as MOPO and MOReL. In the tested scenarios EvC is more robust than the said approaches suggesting that sub-optimally solving an Offline Risk-sensitive Bayesian MDP (ORBMDP) could define a sound framework for planning under model uncertainty.
Offline Learning for Planning: A Summary
Oct 05, 2020

The training of autonomous agents often requires expensive and unsafe trial-and-error interactions with the environment. Nowadays several data sets containing recorded experiences of intelligent agents performing various tasks, spanning from the control of unmanned vehicles to human-robot interaction and medical applications are accessible on the internet. With the intention of limiting the costs of the learning procedure it is convenient to exploit the information that is already available rather than collecting new data. Nevertheless, the incapability to augment the batch can lead the autonomous agents to develop far from optimal behaviours when the sampled experiences do not allow for a good estimate of the true distribution of the environment. Offline learning is the area of machine learning concerned with efficiently obtaining an optimal policy with a batch of previously collected experiences without further interaction with the environment. In this paper we adumbrate the ideas motivating the development of the state-of-the-art offline learning baselines. The listed methods consist in the introduction of epistemic uncertainty dependent constraints during the classical resolution of a Markov Decision Process, with and without function approximators, that aims to alleviate the bad effects of the distributional mismatch between the available samples and real world. We provide comments on the practical utility of the theoretical bounds that justify the application of these algorithms and suggest the utilization of Generative Adversarial Networks to estimate the distributional shift that affects all of the proposed model-free and model-based approaches.