 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Trade-off between Plausibility, Change Intensity and Adversarial Power in Counterfactual Explanations using Multi-objective Optimization
May 20, 2022
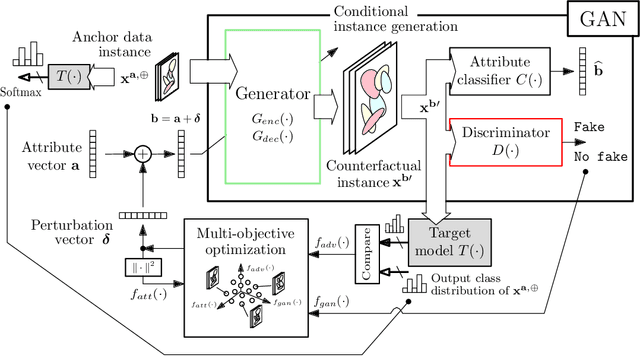

There is a broad consensus on the importance of deep learning models in tasks involving complex data. Often, an adequate understanding of these models is required when focusing on the transparency of decisions in human-critical applications. Besides other explainability techniques, trustworthiness can be achieved by using counterfactuals, like the way a human becomes familiar with an unknown process: by understanding the hypothetical circumstances under which the output changes. In this work we argue that automated counterfactual generation should regard several aspects of the produced adversarial instances, not only their adversarial capability. To this end, we present a novel framework for the generation of counterfactual examples which formulates its goal as a multi-objective optimization problem balancing three different objectives: 1) plausibility, i.e., the likeliness of the counterfactual of being possible as per the distribution of the input data; 2) intensity of the changes to the original input; and 3) adversarial power, namely, the variability of the model's output induced by the counterfactual. The framework departs from a target model to be audited and uses a Generative Adversarial Network to model the distribution of input data, together with a multi-objective solver for the discovery of counterfactuals balancing among these objectives. The utility of the framework is showcased over six classification tasks comprising image and three-dimensional data. The experiments verify that the framework unveils counterfactuals that comply with intuition, increasing the trustworthiness of the user, and leading to further insights, such as the detection of bias and data misrepresentation.
Plausible Counterfactuals: Auditing Deep Learning Classifiers with Realistic Adversarial Examples
Mar 25, 2020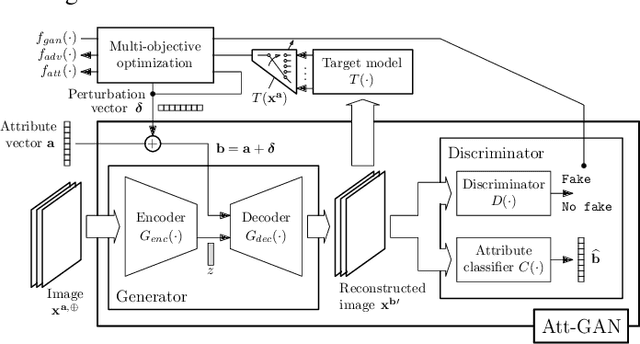

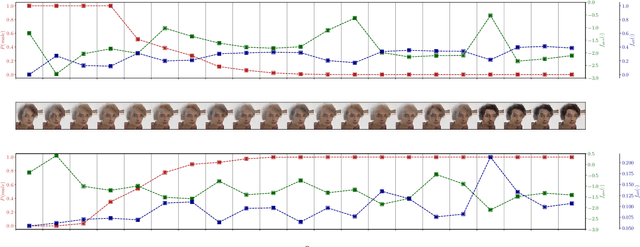
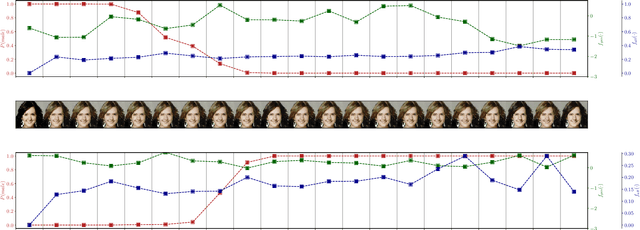
The last decade has witnessed the proliferation of Deep Learning models in many applications, achieving unrivaled levels of predictive performance. Unfortunately, the black-box nature of Deep Learning models has posed unanswered questions about what they learn from data. Certain application scenarios have highlighted the importance of assessing the bounds under which Deep Learning models operate, a problem addressed by using assorted approaches aimed at audiences from different domains. However, as the focus of the application is placed more on non-expert users, it results mandatory to provide the means for him/her to trust the model, just like a human gets familiar with a system or process: by understanding the hypothetical circumstances under which it fails. This is indeed the angular stone for this research work: to undertake an adversarial analysis of a Deep Learning model. The proposed framework constructs counterfactual examples by ensuring their plausibility, e.g. there is a reasonable probability that a human could generate them without resorting to a computer program. Therefore, this work must be regarded as valuable auditing exercise of the usable bounds a certain model is constrained within, thereby allowing for a much greater understanding of the capabilities and pitfalls of a model used in a real application. To this end, a Generative Adversarial Network (GAN) and multi-objective heuristics are used to furnish a plausible attack to the audited model, efficiently trading between the confusion of this model, the intensity and plausibility of the generated counterfactual. Its utility is showcased within a human face classification task, unveiling the enormous potential of the proposed framework.