 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Radar Gaussian Modeling and Scan Matching with RCS
Apr 16, 20264D millimeter-wave (mmWave) radars are increasingly used in robotics, as they offer robustness against adverse environmental conditions. Besides the usual XYZ position, they provide Doppler velocity measurements as well as Radar Cross Section (RCS) information for every point. While Doppler is widely used to filter out dynamic points, RCS is often overlooked and not usually used in modeling and scan matching processes. Building on previous 3D Gaussian modeling and scan matching work, we propose incorporating the physical behavior of RCS in the model, in order to further enrich the summarized information about the scene, and improve the scan matching process.
4D Radar-Inertial Odometry based on Gaussian Modeling and Multi-Hypothesis Scan Matching
Dec 18, 2024



4D millimeter-wave (mmWave) radars are sensors that provide robustness against adverse weather conditions (rain, snow, fog, etc.), and as such they are increasingly being used for odometry and SLAM applications. However, the noisy and sparse nature of the returned scan data proves to be a challenging obstacle for existing point cloud matching based solutions, especially those originally intended for more accurate sensors such as LiDAR. Inspired by visual odometry research around 3D Gaussian Splatting, in this paper we propose using freely positioned 3D Gaussians to create a summarized representation of a radar point cloud tolerant to sensor noise, and subsequently leverage its inherent probability distribution function for registration (similar to NDT). Moreover, we propose simultaneously optimizing multiple scan matching hypotheses in order to further increase the robustness of the system against local optima of the function. Finally, we fuse our Gaussian modeling and scan matching algorithms into an EKF radar-inertial odometry system designed after current best practices. Experiments show that our Gaussian-based odometry is able to outperform current baselines on a well-known 4D radar dataset used for evaluation.
FROG: A new people detection dataset for knee-high 2D range finders
Jun 14, 2023Mobile robots require knowledge of the environment, especially of humans located in its vicinity. While the most common approaches for detecting humans involve computer vision, an often overlooked hardware feature of robots for people detection are their 2D range finders. These were originally intended for obstacle avoidance and mapping/SLAM tasks. In most robots, they are conveniently located at a height approximately between the ankle and the knee, so they can be used for detecting people too, and with a larger field of view and depth resolution compared to cameras. In this paper, we present a new dataset for people detection using knee-high 2D range finders called FROG. This dataset has greater laser resolution, scanning frequency, and more complete annotation data compared to existing datasets such as DROW. Particularly, the FROG dataset contains annotations for 100% of its laser scans (unlike DROW which only annotates 5%), 17x more annotated scans, 100x more people annotations, and over twice the distance traveled by the robot. We propose a benchmark based on the FROG dataset, and analyze a collection of state-of-the-art people detectors based on 2D range finder data. We also propose and evaluate a new end-to-end deep learning approach for people detection. Our solution works with the raw sensor data directly (not needing hand-crafted input data features), thus avoiding CPU preprocessing and releasing the developer of understanding specific domain heuristics. Experimental results show how the proposed people detector attains results comparable to the state of the art, while an optimized implementation for ROS can operate at more than 500 Hz.
OG-SGG: Ontology-Guided Scene Graph Generation. A Case Study in Transfer Learning for Telepresence Robotics
Feb 21, 2022

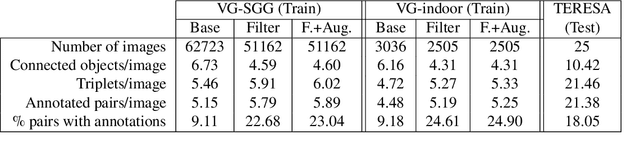
Scene graph generation from images is a task of great interest to applications such as robotics, because graphs are the main way to represent knowledge about the world and regulate human-robot interactions in tasks such as Visual Question Answering (VQA). Unfortunately, its corresponding area of machine learning is still relatively in its infancy, and the solutions currently offered do not specialize well in concrete usage scenarios. Specifically, they do not take existing "expert" knowledge about the domain world into account; and that might indeed be necessary in order to provide the level of reliability demanded by the use case scenarios. In this paper, we propose an initial approximation to a framework called Ontology-Guided Scene Graph Generation (OG-SGG), that can improve the performance of an existing machine learning based scene graph generator using prior knowledge supplied in the form of an ontology; and we present results evaluated on a specific scenario founded in telepresence robotics.