 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuNavSim 2.0
Jul 23, 2025This work presents a new iteration of the Human Navigation Simulator (HuNavSim), a novel open-source tool for the simulation of different human-agent navigation behaviors in scenarios with mobile robots. The tool, programmed under the ROS 2 framework, can be used together with different well-known robotics simulators such as Gazebo or NVidia Isaac Sim. The main goal is to facilitate the development and evaluation of human-aware robot navigation systems in simulation. In this new version, several features have been improved and new ones added, such as the extended set of actions and conditions that can be combined in Behavior Trees to compound complex and realistic human behaviors.
Adaptive Social Force Window Planner with Reinforcement Learning
Apr 21, 2024Human-aware navigation is a complex task for mobile robots, requiring an autonomous navigation system capable of achieving efficient path planning together with socially compliant behaviors. Social planners usually add costs or constraints to the objective function, leading to intricate tuning processes or tailoring the solution to the specific social scenario. Machine Learning can enhance planners' versatility and help them learn complex social behaviors from data. This work proposes an adaptive social planner, using a Deep Reinforcement Learning agent to dynamically adjust the weighting parameters of the cost function used to evaluate trajectories. The resulting planner combines the robustness of the classic Dynamic Window Approach, integrated with a social cost based on the Social Force Model, and the flexibility of learning methods to boost the overall performance on social navigation tasks. Our extensive experimentation on different environments demonstrates the general advantage of the proposed method over static cost planners.
FROG: A new people detection dataset for knee-high 2D range finders
Jun 14, 2023Mobile robots require knowledge of the environment, especially of humans located in its vicinity. While the most common approaches for detecting humans involve computer vision, an often overlooked hardware feature of robots for people detection are their 2D range finders. These were originally intended for obstacle avoidance and mapping/SLAM tasks. In most robots, they are conveniently located at a height approximately between the ankle and the knee, so they can be used for detecting people too, and with a larger field of view and depth resolution compared to cameras. In this paper, we present a new dataset for people detection using knee-high 2D range finders called FROG. This dataset has greater laser resolution, scanning frequency, and more complete annotation data compared to existing datasets such as DROW. Particularly, the FROG dataset contains annotations for 100% of its laser scans (unlike DROW which only annotates 5%), 17x more annotated scans, 100x more people annotations, and over twice the distance traveled by the robot. We propose a benchmark based on the FROG dataset, and analyze a collection of state-of-the-art people detectors based on 2D range finder data. We also propose and evaluate a new end-to-end deep learning approach for people detection. Our solution works with the raw sensor data directly (not needing hand-crafted input data features), thus avoiding CPU preprocessing and releasing the developer of understanding specific domain heuristics. Experimental results show how the proposed people detector attains results comparable to the state of the art, while an optimized implementation for ROS can operate at more than 500 Hz.
HuNavSim: A ROS 2 Human Navigation Simulator for Benchmarking Human-Aware Robot Navigation
May 02, 2023

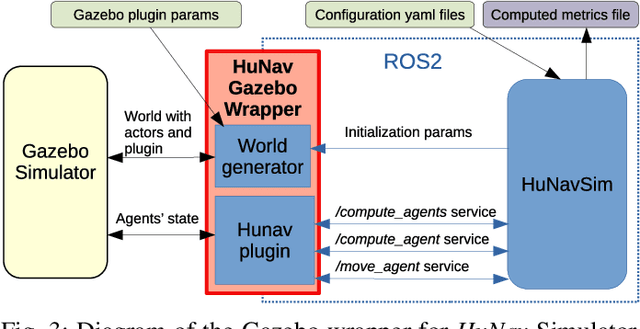

This work presents the Human Navigation Simulator (HuNavSim), a novel open-source tool for the simulation of different human-agent navigation behaviors in scenarios with mobile robots. The tool, the first programmed under the ROS 2 framework, can be employed along with different well-known robotics simulators like Gazebo. The main goal is to ease the development and evaluation of human-aware robot navigation systems in simulation. Besides a general human-navigation model, HuNavSim includes, as a novelty, a rich set of individual and realistic human navigation behaviors and a complete set of metrics for social navigation benchmarking.
Learning Human-Aware Path Planning with Fully Convolutional Networks
Jul 17, 2018
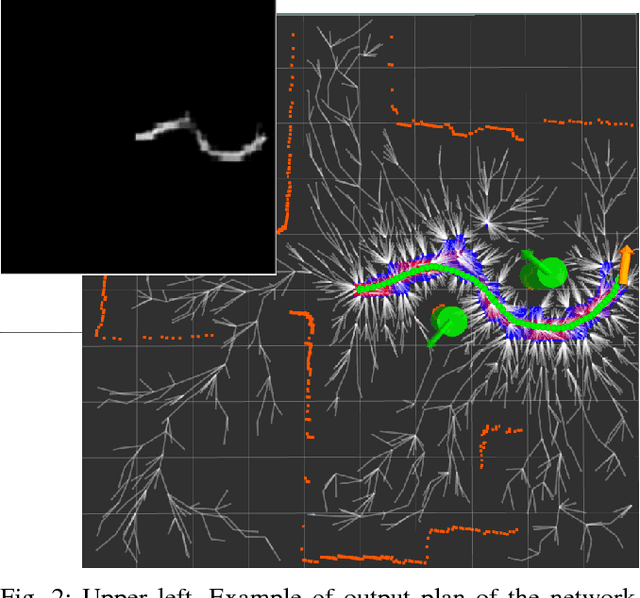
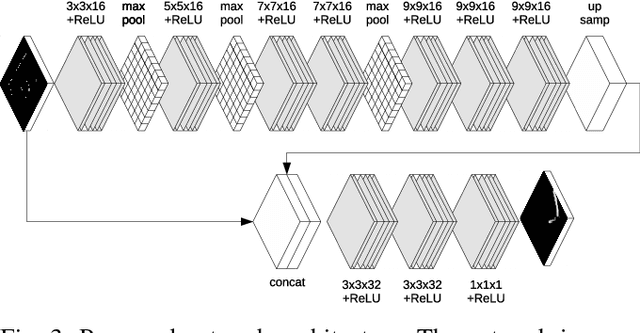

This work presents an approach to learn path planning for robot social navigation by demonstration. We make use of Fully Convolutional Neural Networks (FCNs) to learn from expert's path demonstrations a map that marks a feasible path to the goal as a classification problem. The use of FCNs allows us to overcome the problem of manually designing/identifying the cost-map and relevant features for the task of robot navigation. The method makes use of optimal Rapidly-exploring Random Tree planner (RRT*) to overcome eventual errors in the path prediction; the FCNs prediction is used as cost-map and also to partially bias the sampling of the configuration space, leading the planner to behave similarly to the learned expert behavior. The approach is evaluated in experiments with real trajectories and compared with Inverse Reinforcement Learning algorithms that use RRT* as underlying planner.