 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep ROC Analysis and AUC as Balanced Average Accuracy to Improve Model Selection, Understanding and Interpretation
Mar 21, 2021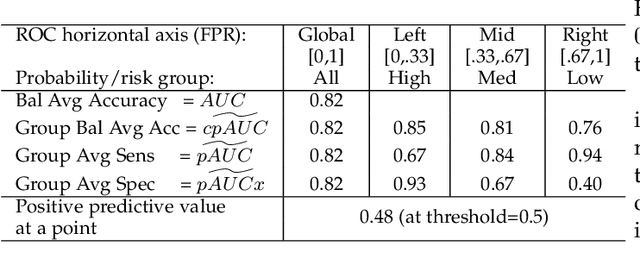
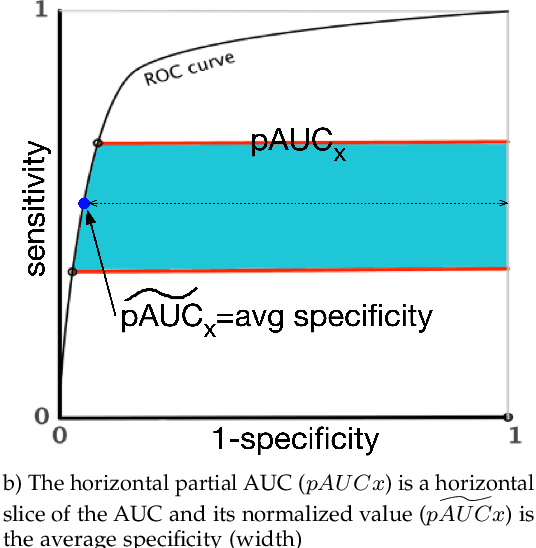
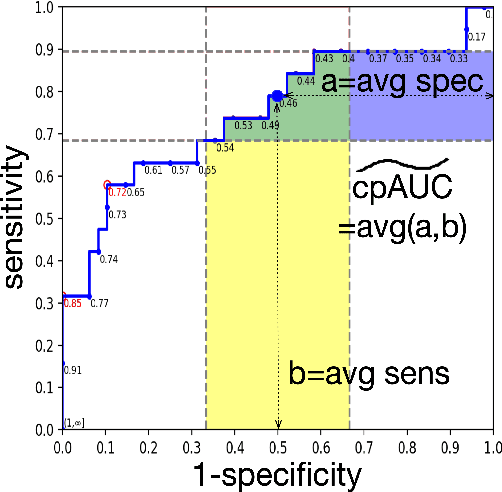
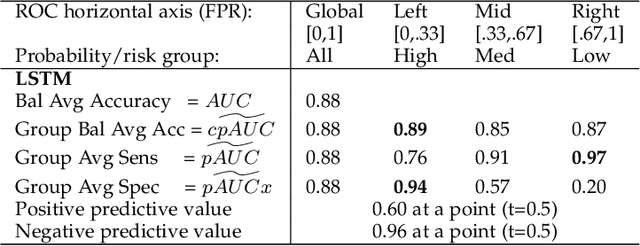
Optimal performance is critical for decision-making tasks from medicine to autonomous driving, however common performance measures may be too general or too specific. For binary classifiers, diagnostic tests or prognosis at a timepoint, measures such as the area under the receiver operating characteristic curve, or the area under the precision recall curve, are too general because they include unrealistic decision thresholds. On the other hand, measures such as accuracy, sensitivity or the F1 score are measures at a single threshold that reflect an individual single probability or predicted risk, rather than a range of individuals or risk. We propose a method in between, deep ROC analysis, that examines groups of probabilities or predicted risks for more insightful analysis. We translate esoteric measures into familiar terms: AUC and the normalized concordant partial AUC are balanced average accuracy (a new finding); the normalized partial AUC is average sensitivity; and the normalized horizontal partial AUC is average specificity. Along with post-test measures, we provide a method that can improve model selection in some cases and provide interpretation and assurance for patients in each risk group. We demonstrate deep ROC analysis in two case studies and provide a toolkit in Python.