 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRUSTED: The Paired 3D Transabdominal Ultrasound and CT Human Data for Kidney Segmentation and Registration Research
Oct 19, 2023Inter-modal image registration (IMIR) and image segmentation with abdominal Ultrasound (US) data has many important clinical applications, including image-guided surgery, automatic organ measurement and robotic navigation. However, research is severely limited by the lack of public datasets. We propose TRUSTED (the Tridimensional Renal Ultra Sound TomodEnsitometrie Dataset), comprising paired transabdominal 3DUS and CT kidney images from 48 human patients (96 kidneys), including segmentation, and anatomical landmark annotations by two experienced radiographers. Inter-rater segmentation agreement was over 94 (Dice score), and gold-standard segmentations were generated using the STAPLE algorithm. Seven anatomical landmarks were annotated, important for IMIR systems development and evaluation. To validate the dataset's utility, 5 competitive Deep Learning models for automatic kidney segmentation were benchmarked, yielding average DICE scores from 83.2% to 89.1% for CT, and 61.9% to 79.4% for US images. Three IMIR methods were benchmarked, and Coherent Point Drift performed best with an average Target Registration Error of 4.53mm. The TRUSTED dataset may be used freely researchers to develop and validate new segmentation and IMIR methods.
Full Contextual Attention for Multi-resolution Transformers in Semantic Segmentation
Dec 15, 2022



Transformers have proved to be very effective for visual recognition tasks. In particular, vision transformers construct compressed global representations through self-attention and learnable class tokens. Multi-resolution transformers have shown recent successes in semantic segmentation but can only capture local interactions in high-resolution feature maps. This paper extends the notion of global tokens to build GLobal Attention Multi-resolution (GLAM) transformers. GLAM is a generic module that can be integrated into most existing transformer backbones. GLAM includes learnable global tokens, which unlike previous methods can model interactions between all image regions, and extracts powerful representations during training. Extensive experiments show that GLAM-Swin or GLAM-Swin-UNet exhibit substantially better performances than their vanilla counterparts on ADE20K and Cityscapes. Moreover, GLAM can be used to segment large 3D medical images, and GLAM-nnFormer achieves new state-of-the-art performance on the BCV dataset.
Memory transformers for full context and high-resolution 3D Medical Segmentation
Oct 11, 2022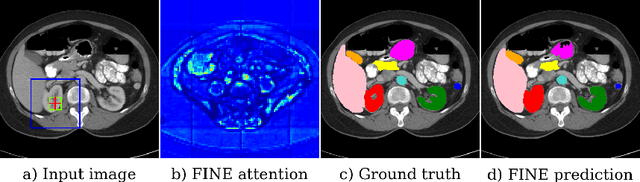
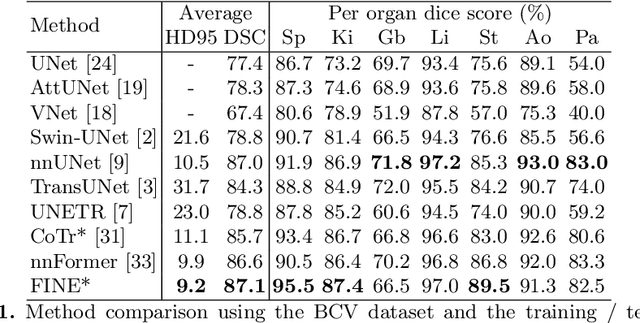
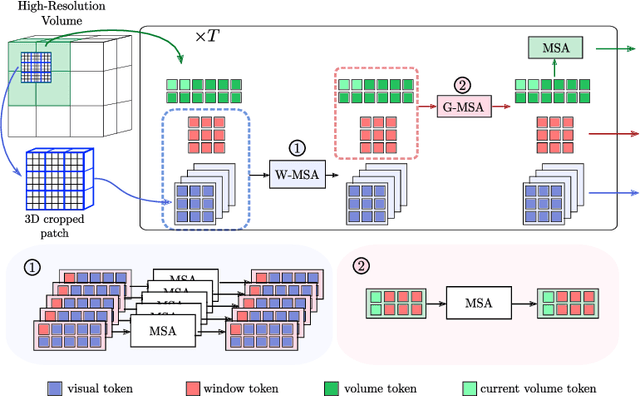

Transformer models achieve state-of-the-art results for image segmentation. However, achieving long-range attention, necessary to capture global context, with high-resolution 3D images is a fundamental challenge. This paper introduces the Full resolutIoN mEmory (FINE) transformer to overcome this issue. The core idea behind FINE is to learn memory tokens to indirectly model full range interactions while scaling well in both memory and computational costs. FINE introduces memory tokens at two levels: the first one allows full interaction between voxels within local image regions (patches), the second one allows full interactions between all regions of the 3D volume. Combined, they allow full attention over high resolution images, e.g. 512 x 512 x 256 voxels and above. Experiments on the BCV image segmentation dataset shows better performances than state-of-the-art CNN and transformer baselines, highlighting the superiority of our full attention mechanism compared to recent transformer baselines, e.g. CoTr, and nnFormer.