 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Multi-centric Generalization: Phase and Step Recognition in Roux-en-Y Gastric Bypass Surgery
Dec 18, 2023Most studies on surgical activity recognition utilizing Artificial intelligence (AI) have focused mainly on recognizing one type of activity from small and mono-centric surgical video datasets. It remains speculative whether those models would generalize to other centers. In this work, we introduce a large multi-centric multi-activity dataset consisting of 140 videos (MultiBypass140) of laparoscopic Roux-en-Y gastric bypass (LRYGB) surgeries performed at two medical centers: the University Hospital of Strasbourg (StrasBypass70) and Inselspital, Bern University Hospital (BernBypass70). The dataset has been fully annotated with phases and steps. Furthermore, we assess the generalizability and benchmark different deep learning models in 7 experimental studies: 1) Training and evaluation on BernBypass70; 2) Training and evaluation on StrasBypass70; 3) Training and evaluation on the MultiBypass140; 4) Training on BernBypass70, evaluation on StrasBypass70; 5) Training on StrasBypass70, evaluation on BernBypass70; Training on MultiBypass140, evaluation 6) on BernBypass70 and 7) on StrasBypass70. The model's performance is markedly influenced by the training data. The worst results were obtained in experiments 4) and 5) confirming the limited generalization capabilities of models trained on mono-centric data. The use of multi-centric training data, experiments 6) and 7), improves the generalization capabilities of the models, bringing them beyond the level of independent mono-centric training and validation (experiments 1) and 2)). MultiBypass140 shows considerable variation in surgical technique and workflow of LRYGB procedures between centers. Therefore, generalization experiments demonstrate a remarkable difference in model performance. These results highlight the importance of multi-centric datasets for AI model generalization to account for variance in surgical technique and workflows.
Weakly Supervised Temporal Convolutional Networks for Fine-grained Surgical Activity Recognition
Feb 21, 2023



Automatic recognition of fine-grained surgical activities, called steps, is a challenging but crucial task for intelligent intra-operative computer assistance. The development of current vision-based activity recognition methods relies heavily on a high volume of manually annotated data. This data is difficult and time-consuming to generate and requires domain-specific knowledge. In this work, we propose to use coarser and easier-to-annotate activity labels, namely phases, as weak supervision to learn step recognition with fewer step annotated videos. We introduce a step-phase dependency loss to exploit the weak supervision signal. We then employ a Single-Stage Temporal Convolutional Network (SS-TCN) with a ResNet-50 backbone, trained in an end-to-end fashion from weakly annotated videos, for temporal activity segmentation and recognition. We extensively evaluate and show the effectiveness of the proposed method on a large video dataset consisting of 40 laparoscopic gastric bypass procedures and the public benchmark CATARACTS containing 50 cataract surgeries.
CholecTriplet2022: Show me a tool and tell me the triplet -- an endoscopic vision challenge for surgical action triplet detection
Feb 13, 2023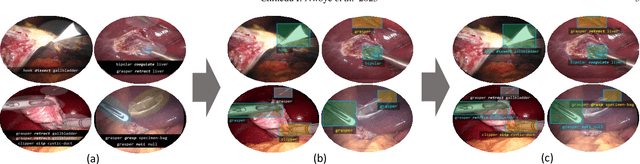
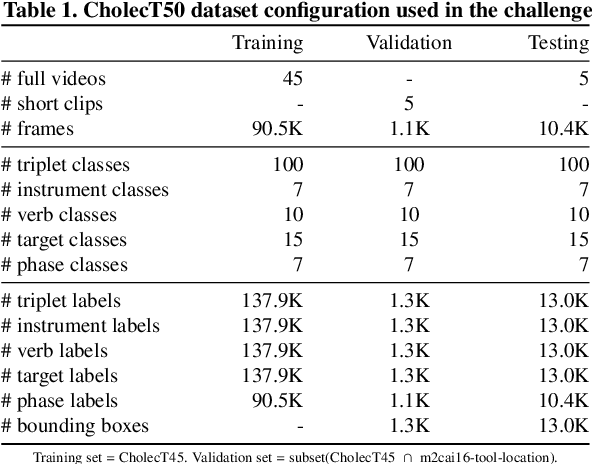
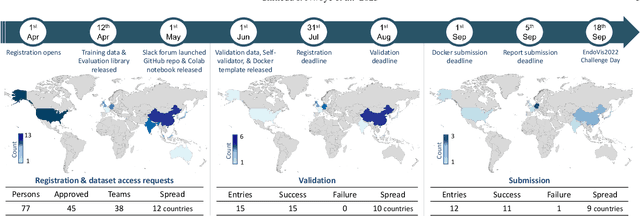
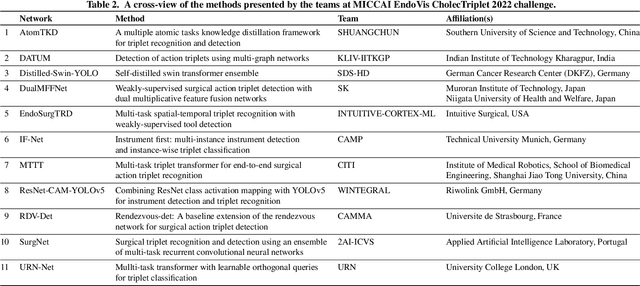
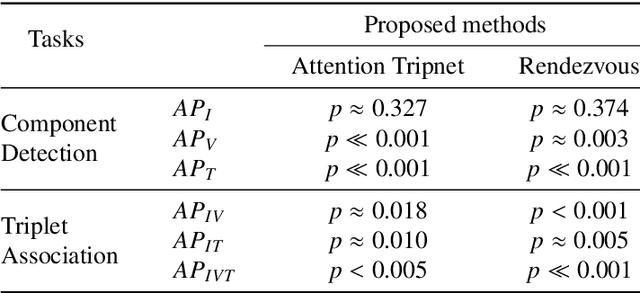
Formalizing surgical activities as triplets of the used instruments, actions performed, and target anatomies is becoming a gold standard approach for surgical activity modeling. The benefit is that this formalization helps to obtain a more detailed understanding of tool-tissue interaction which can be used to develop better Artificial Intelligence assistance for image-guided surgery. Earlier efforts and the CholecTriplet challenge introduced in 2021 have put together techniques aimed at recognizing these triplets from surgical footage. Estimating also the spatial locations of the triplets would offer a more precise intraoperative context-aware decision support for computer-assisted intervention. This paper presents the CholecTriplet2022 challenge, which extends surgical action triplet modeling from recognition to detection. It includes weakly-supervised bounding box localization of every visible surgical instrument (or tool), as the key actors, and the modeling of each tool-activity in the form of <instrument, verb, target> triplet. The paper describes a baseline method and 10 new deep learning algorithms presented at the challenge to solve the task. It also provides thorough methodological comparisons of the methods, an in-depth analysis of the obtained results, their significance, and useful insights for future research directions and applications in surgery.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022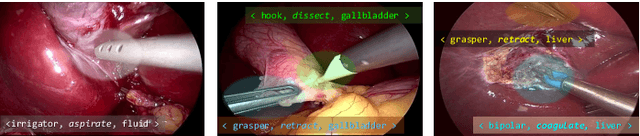

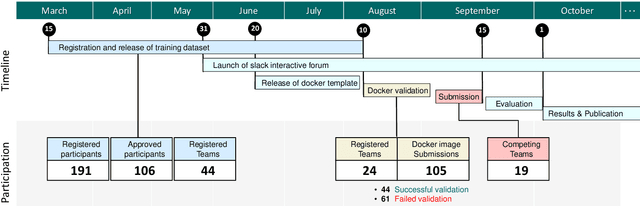
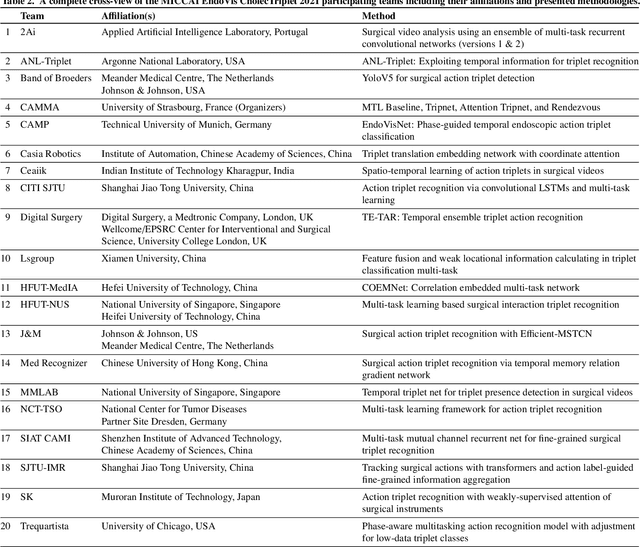
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Rendezvous: Attention Mechanisms for the Recognition of Surgical Action Triplets in Endoscopic Videos
Sep 07, 2021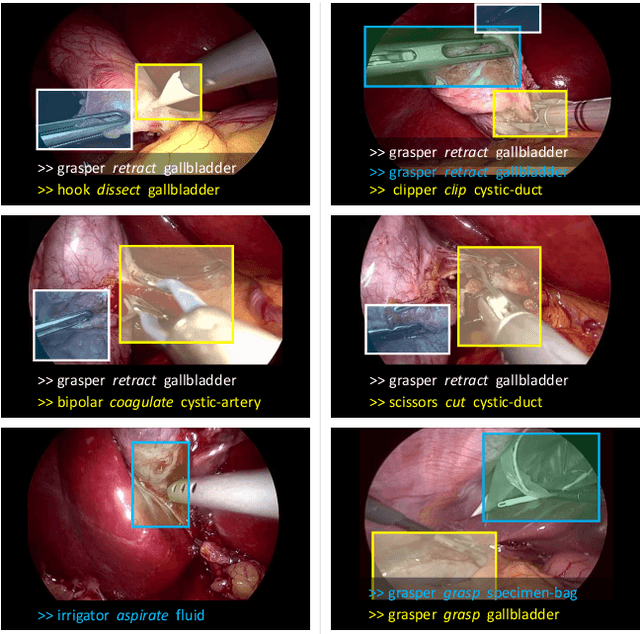
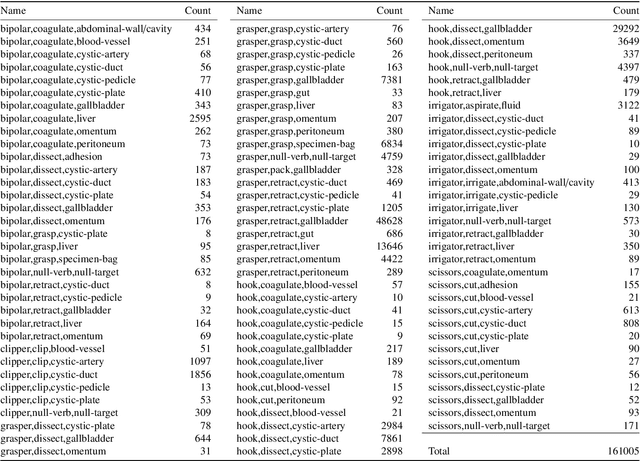
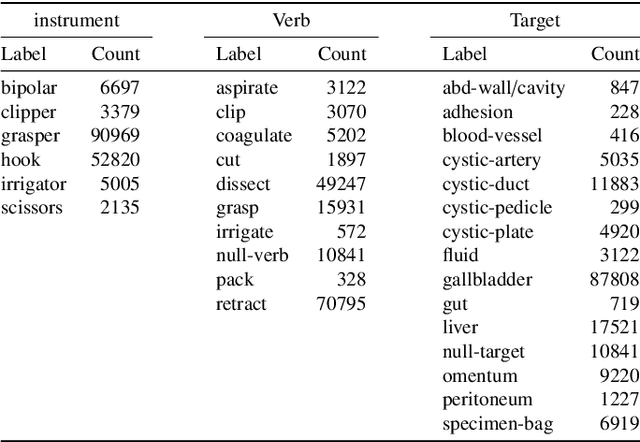
Out of all existing frameworks for surgical workflow analysis in endoscopic videos, action triplet recognition stands out as the only one aiming to provide truly fine-grained and comprehensive information on surgical activities. This information, presented as <instrument, verb, target> combinations, is highly challenging to be accurately identified. Triplet components can be difficult to recognize individually; in this task, it requires not only performing recognition simultaneously for all three triplet components, but also correctly establishing the data association between them. To achieve this task, we introduce our new model, the Rendezvous (RDV), which recognizes triplets directly from surgical videos by leveraging attention at two different levels. We first introduce a new form of spatial attention to capture individual action triplet components in a scene; called the Class Activation Guided Attention Mechanism (CAGAM). This technique focuses on the recognition of verbs and targets using activations resulting from instruments. To solve the association problem, our RDV model adds a new form of semantic attention inspired by Transformer networks. Using multiple heads of cross and self attentions, RDV is able to effectively capture relationships between instruments, verbs, and targets. We also introduce CholecT50 - a dataset of 50 endoscopic videos in which every frame has been annotated with labels from 100 triplet classes. Our proposed RDV model significantly improves the triplet prediction mAP by over 9% compared to the state-of-the-art methods on this dataset.
Multi-Task Temporal Convolutional Networks for Joint Recognition of Surgical Phases and Steps in Gastric Bypass Procedures
Feb 24, 2021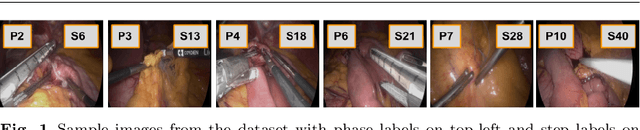
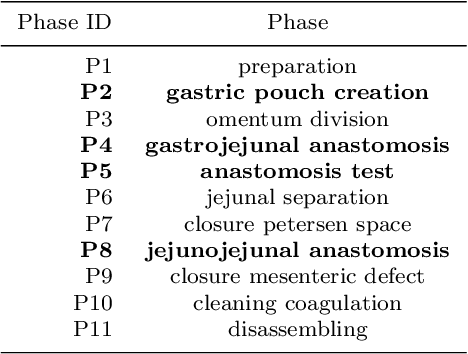


Purpose: Automatic segmentation and classification of surgical activity is crucial for providing advanced support in computer-assisted interventions and autonomous functionalities in robot-assisted surgeries. Prior works have focused on recognizing either coarse activities, such as phases, or fine-grained activities, such as gestures. This work aims at jointly recognizing two complementary levels of granularity directly from videos, namely phases and steps. Method: We introduce two correlated surgical activities, phases and steps, for the laparoscopic gastric bypass procedure. We propose a Multi-task Multi-Stage Temporal Convolutional Network (MTMS-TCN) along with a multi-task Convolutional Neural Network (CNN) training setup to jointly predict the phases and steps and benefit from their complementarity to better evaluate the execution of the procedure. We evaluate the proposed method on a large video dataset consisting of 40 surgical procedures (Bypass40). Results: We present experimental results from several baseline models for both phase and step recognition on the Bypass40 dataset. The proposed MTMS-TCN method outperforms in both phase and step recognition by 1-2% in accuracy, precision and recall, compared to single-task methods. Furthermore, for step recognition, MTMS-TCN achieves a superior performance of 3-6% compared to LSTM based models in accuracy, precision, and recall. Conclusion: In this work, we present a multi-task multi-stage temporal convolutional network for surgical activity recognition, which shows improved results compared to single-task models on the Bypass40 gastric bypass dataset with multi-level annotations. The proposed method shows that the joint modeling of phases and steps is beneficial to improve the overall recognition of each type of activity.
Recognition of Instrument-Tissue Interactions in Endoscopic Videos via Action Triplets
Jul 10, 2020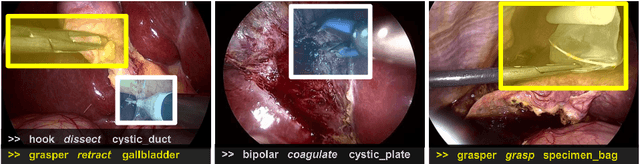
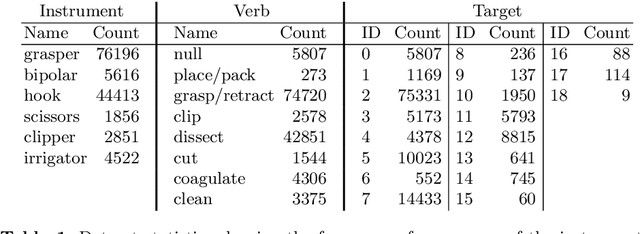

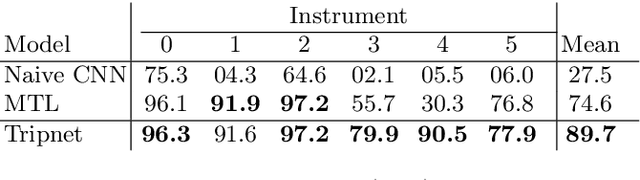
Recognition of surgical activity is an essential component to develop context-aware decision support for the operating room. In this work, we tackle the recognition of fine-grained activities, modeled as action triplets <instrument, verb, target> representing the tool activity. To this end, we introduce a new laparoscopic dataset, CholecT40, consisting of 40 videos from the public dataset Cholec80 in which all frames have been annotated using 128 triplet classes. Furthermore, we present an approach to recognize these triplets directly from the video data. It relies on a module called Class Activation Guide (CAG), which uses the instrument activation maps to guide the verb and target recognition. To model the recognition of multiple triplets in the same frame, we also propose a trainable 3D Interaction Space, which captures the associations between the triplet components. Finally, we demonstrate the significance of these contributions via several ablation studies and comparisons to baselines on CholecT40.