 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Sequential Causal Optimization of Process Interventions
Dec 22, 2025



Prescriptive Process Monitoring (PresPM) recommends interventions during business processes to optimize key performance indicators (KPIs). In realistic settings, interventions are rarely isolated: organizations need to align sequences of interventions to jointly steer the outcome of a case. Existing PresPM approaches fall short in this respect. Many focus on a single intervention decision, while others treat multiple interventions independently, ignoring how they interact over time. Methods that do address these dependencies depend either on simulation or data augmentation to approximate the process to train a Reinforcement Learning (RL) agent, which can create a reality gap and introduce bias. We introduce SCOPE, a PresPM approach that learns aligned sequential intervention recommendations. SCOPE employs backward induction to estimate the effect of each candidate intervention action, propagating its impact from the final decision point back to the first. By leveraging causal learners, our method can utilize observational data directly, unlike methods that require constructing process approximations for reinforcement learning. Experiments on both an existing synthetic dataset and a new semi-synthetic dataset show that SCOPE consistently outperforms state-of-the-art PresPM techniques in optimizing the KPI. The novel semi-synthetic setup, based on a real-life event log, is provided as a reusable benchmark for future work on sequential PresPM.
Timing Process Interventions with Causal Inference and Reinforcement Learning
Jun 07, 2023The shift from the understanding and prediction of processes to their optimization offers great benefits to businesses and other organizations. Precisely timed process interventions are the cornerstones of effective optimization. Prescriptive process monitoring (PresPM) is the sub-field of process mining that concentrates on process optimization. The emerging PresPM literature identifies state-of-the-art methods, causal inference (CI) and reinforcement learning (RL), without presenting a quantitative comparison. Most experiments are carried out using historical data, causing problems with the accuracy of the methods' evaluations and preempting online RL. Our contribution consists of experiments on timed process interventions with synthetic data that renders genuine online RL and the comparison to CI possible, and allows for an accurate evaluation of the results. Our experiments reveal that RL's policies outperform those from CI and are more robust at the same time. Indeed, the RL policies approach perfect policies. Unlike CI, the unaltered online RL approach can be applied to other, more generic PresPM problems such as next best activity recommendations. Nonetheless, CI has its merits in settings where online learning is not an option.
Learning Uncertainty with Artificial Neural Networks for Improved Predictive Process Monitoring
Jun 13, 2022

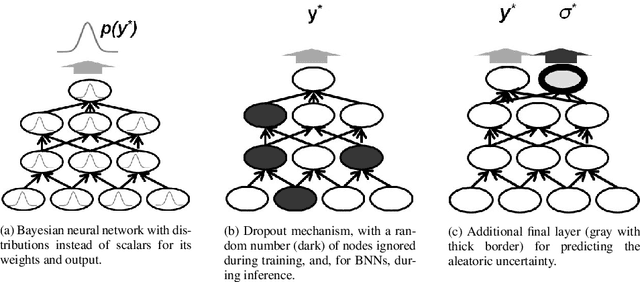
The inability of artificial neural networks to assess the uncertainty of their predictions is an impediment to their widespread use. We distinguish two types of learnable uncertainty: model uncertainty due to a lack of training data and noise-induced observational uncertainty. Bayesian neural networks use solid mathematical foundations to learn the model uncertainties of their predictions. The observational uncertainty can be calculated by adding one layer to these networks and augmenting their loss functions. Our contribution is to apply these uncertainty concepts to predictive process monitoring tasks to train uncertainty-based models to predict the remaining time and outcomes. Our experiments show that uncertainty estimates allow more and less accurate predictions to be differentiated and confidence intervals to be constructed in both regression and classification tasks. These conclusions remain true even in early stages of running processes. Moreover, the deployed techniques are fast and produce more accurate predictions. The learned uncertainty could increase users' confidence in their process prediction systems, promote better cooperation between humans and these systems, and enable earlier implementations with smaller datasets.
Creating Unbiased Public Benchmark Datasets with Data Leakage Prevention for Predictive Process Monitoring
Jul 05, 2021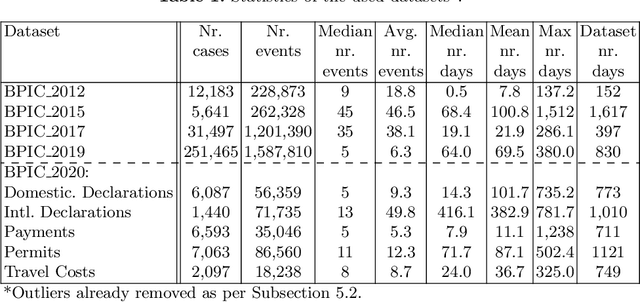
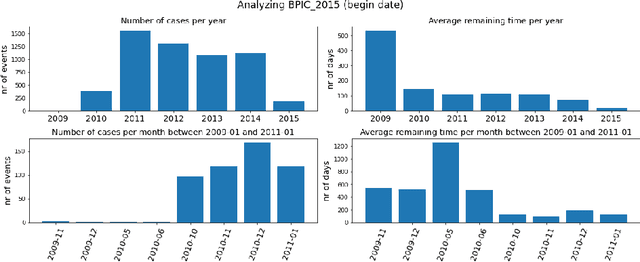
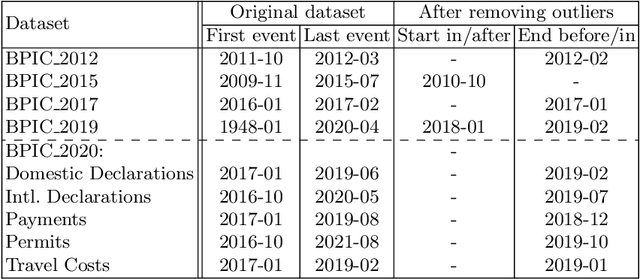
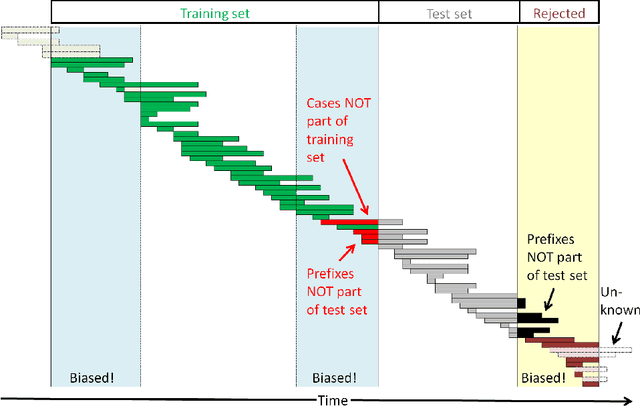
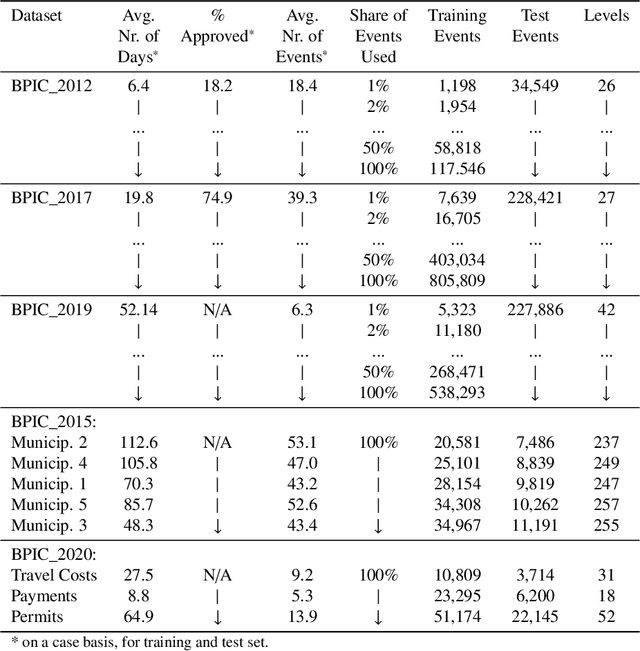
Advances in AI, and especially machine learning, are increasingly drawing research interest and efforts towards predictive process monitoring, the subfield of process mining (PM) that concerns predicting next events, process outcomes and remaining execution times. Unfortunately, researchers use a variety of datasets and ways to split them into training and test sets. The documentation of these preprocessing steps is not always complete. Consequently, research results are hard or even impossible to reproduce and to compare between papers. At times, the use of non-public domain knowledge further hampers the fair competition of ideas. Often the training and test sets are not completely separated, a data leakage problem particular to predictive process monitoring. Moreover, test sets usually suffer from bias in terms of both the mix of case durations and the number of running cases. These obstacles pose a challenge to the field's progress. The contribution of this paper is to identify and demonstrate the importance of these obstacles and to propose preprocessing steps to arrive at unbiased benchmark datasets in a principled way, thus creating representative test sets without data leakage with the aim of levelling the playing field, promoting open science and contributing to more rapid progress in predictive process monitoring.
Learning Uncertainty with Artificial Neural Networks for Improved Remaining Time Prediction of Business Processes
May 12, 2021

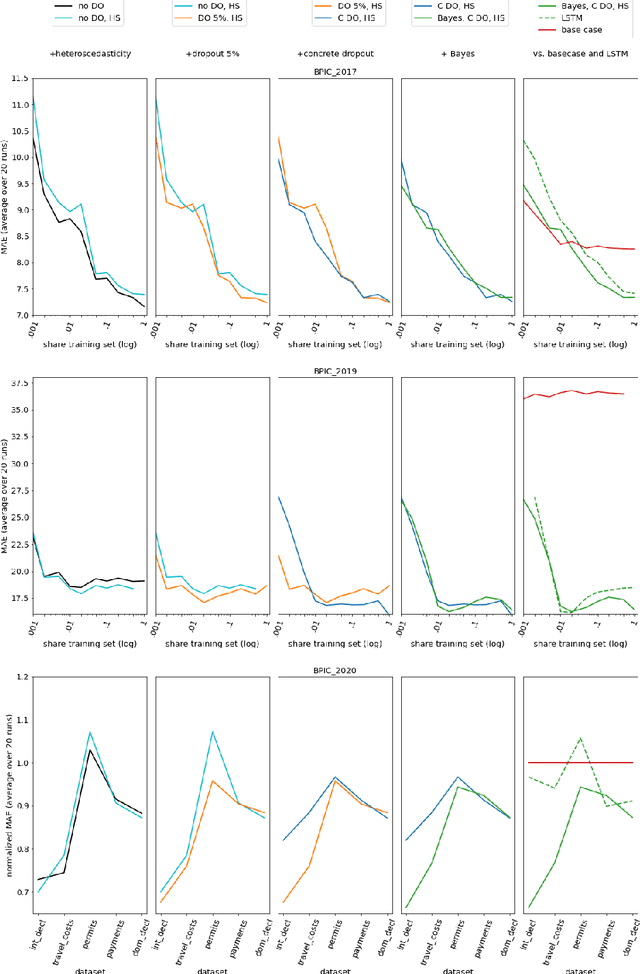
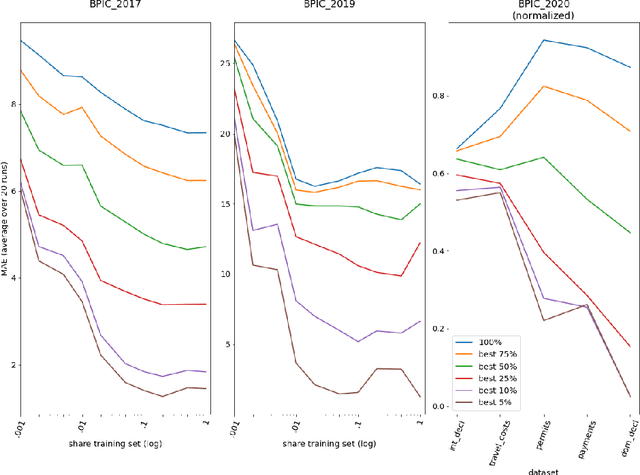
Artificial neural networks will always make a prediction, even when completely uncertain and regardless of the consequences. This obliviousness of uncertainty is a major obstacle towards their adoption in practice. Techniques exist, however, to estimate the two major types of uncertainty: model uncertainty and observation noise in the data. Bayesian neural networks are theoretically well-founded models that can learn the model uncertainty of their predictions. Minor modifications to these models and their loss functions allow learning the observation noise for individual samples as well. This paper is the first to apply these techniques to predictive process monitoring. We found that they contribute towards more accurate predictions and work quickly. However, their main benefit resides with the uncertainty estimates themselves that allow the separation of higher-quality from lower-quality predictions and the building of confidence intervals. This leads to many interesting applications, enables an earlier adoption of prediction systems with smaller datasets and fosters a better cooperation with humans.
Process Outcome Prediction: CNN vs. LSTM (with Attention)
Apr 14, 2021



The early outcome prediction of ongoing or completed processes confers competitive advantage to organizations. The performance of classic machine learning and, more recently, deep learning techniques such as Long Short-Term Memory (LSTM) on this type of classification problem has been thorougly investigated. Recently, much research focused on applying Convolutional Neural Networks (CNN) to time series problems including classification, however not yet to outcome prediction. The purpose of this paper is to close this gap and compare CNNs to LSTMs. Attention is another technique that, in combination with LSTMs, has found application in time series classification and was included in our research. Our findings show that all these neural networks achieve satisfactory to high predictive power provided sufficiently large datasets. CNNs perfom on par with LSTMs; the Attention mechanism adds no value to the latter. Since CNNs run one order of magnitude faster than both types of LSTM, their use is preferable. All models are robust with respect to their hyperparameters and achieve their maximal predictive power early on in the cases, usually after only a few events, making them highly suitable for runtime predictions. We argue that CNNs' speed, early predictive power and robustness should pave the way for their application in process outcome prediction.