 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll That Glitters Is Not Gold: Towards Process Discovery Techniques with Guarantees
Dec 23, 2020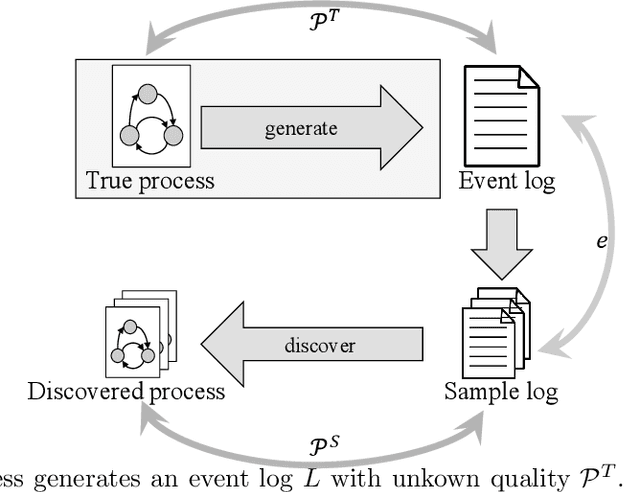

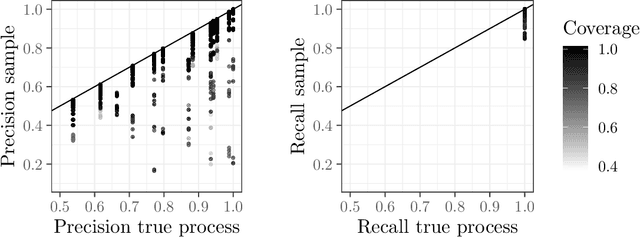
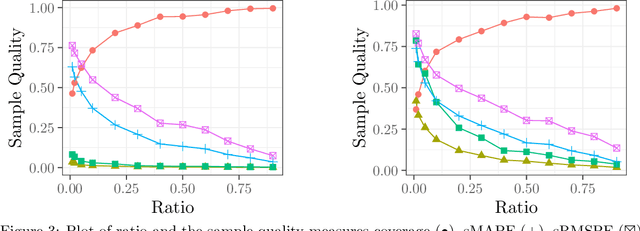
The aim of a process discovery algorithm is to construct from event data a process model that describes the underlying, real-world process well. Intuitively, the better the quality of the event data, the better the quality of the model that is discovered. However, existing process discovery algorithms do not guarantee this relationship. We demonstrate this by using a range of quality measures for both event data and discovered process models. This paper is a call to the community of IS engineers to complement their process discovery algorithms with properties that relate qualities of their inputs to those of their outputs. To this end, we distinguish four incremental stages for the development of such algorithms, along with concrete guidelines for the formulation of relevant properties and experimental validation. We will also use these stages to reflect on the state of the art, which shows the need to move forward in our thinking about algorithmic process discovery.
Contrastive Explanations with Local Foil Trees
Jun 19, 2018
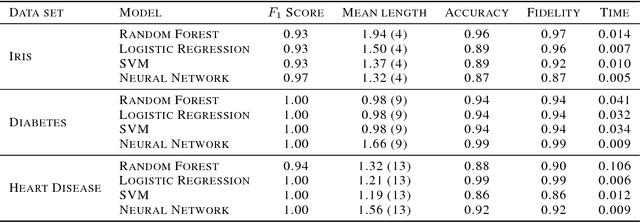
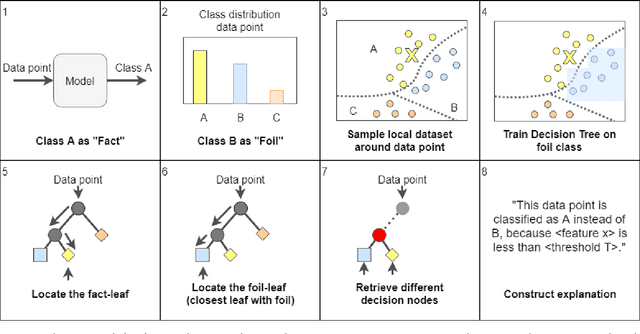
Recent advances in interpretable Machine Learning (iML) and eXplainable AI (XAI) construct explanations based on the importance of features in classification tasks. However, in a high-dimensional feature space this approach may become unfeasible without restraining the set of important features. We propose to utilize the human tendency to ask questions like "Why this output (the fact) instead of that output (the foil)?" to reduce the number of features to those that play a main role in the asked contrast. Our proposed method utilizes locally trained one-versus-all decision trees to identify the disjoint set of rules that causes the tree to classify data points as the foil and not as the fact. In this study we illustrate this approach on three benchmark classification tasks.