 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Explabox: Model-Agnostic Machine Learning Transparency & Analysis
Nov 22, 2024We present the Explabox: an open-source toolkit for transparent and responsible machine learning (ML) model development and usage. Explabox aids in achieving explainable, fair and robust models by employing a four-step strategy: explore, examine, explain and expose. These steps offer model-agnostic analyses that transform complex 'ingestibles' (models and data) into interpretable 'digestibles'. The toolkit encompasses digestibles for descriptive statistics, performance metrics, model behavior explanations (local and global), and robustness, security, and fairness assessments. Implemented in Python, Explabox supports multiple interaction modes and builds on open-source packages. It empowers model developers and testers to operationalize explainability, fairness, auditability, and security. The initial release focuses on text data and models, with plans for expansion. Explabox's code and documentation are available open-source at https://explabox.readthedocs.io/.
Contrastive Explanations with Local Foil Trees
Jun 19, 2018
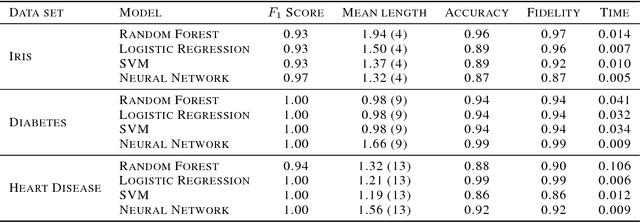
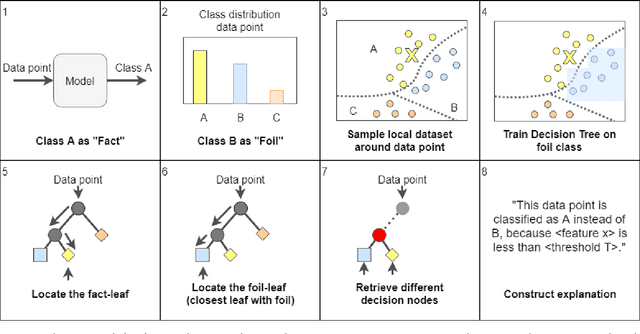
Recent advances in interpretable Machine Learning (iML) and eXplainable AI (XAI) construct explanations based on the importance of features in classification tasks. However, in a high-dimensional feature space this approach may become unfeasible without restraining the set of important features. We propose to utilize the human tendency to ask questions like "Why this output (the fact) instead of that output (the foil)?" to reduce the number of features to those that play a main role in the asked contrast. Our proposed method utilizes locally trained one-versus-all decision trees to identify the disjoint set of rules that causes the tree to classify data points as the foil and not as the fact. In this study we illustrate this approach on three benchmark classification tasks.