 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Learned Sparse Retrieval with Corpus-Specific Vocabularies
Jan 12, 2024We explore leveraging corpus-specific vocabularies that improve both efficiency and effectiveness of learned sparse retrieval systems. We find that pre-training the underlying BERT model on the target corpus, specifically targeting different vocabulary sizes incorporated into the document expansion process, improves retrieval quality by up to 12% while in some scenarios decreasing latency by up to 50%. Our experiments show that adopting corpus-specific vocabulary and increasing vocabulary size decreases average postings list length which in turn reduces latency. Ablation studies show interesting interactions between custom vocabularies, document expansion techniques, and sparsification objectives of sparse models. Both effectiveness and efficiency improvements transfer to different retrieval approaches such as uniCOIL and SPLADE and offer a simple yet effective approach to providing new efficiency-effectiveness trade-offs for learned sparse retrieval systems.
A Sensitivity Analysis of the MSMARCO Passage Collection
Jan 11, 2022

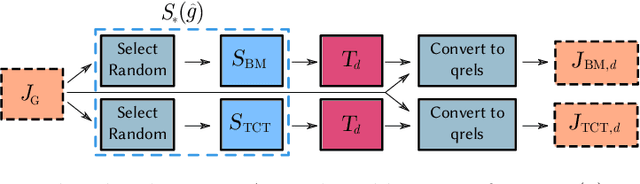
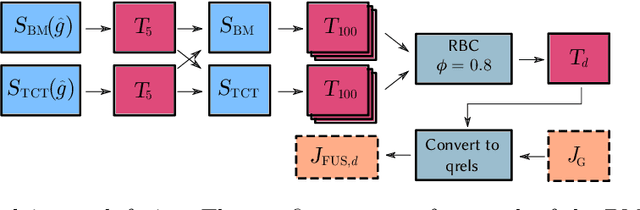
The recent MSMARCO passage retrieval collection has allowed researchers to develop highly tuned retrieval systems. One aspect of this data set that makes it distinctive compared to traditional corpora is that most of the topics only have a single answer passage marked relevant. Here we carry out a "what if" sensitivity study, asking whether a set of systems would still have the same relative performance if more passages per topic were deemed to be "relevant", exploring several mechanisms for identifying sets of passages to be so categorized. Our results show that, in general, while run scores can vary markedly if additional plausible passages are presumed to be relevant, the derived system ordering is relatively insensitive to additional relevance, providing support for the methodology that was used at the time the MSMARCO passage collection was created.
Anytime Ranking on Document-Ordered Indexes
Apr 18, 2021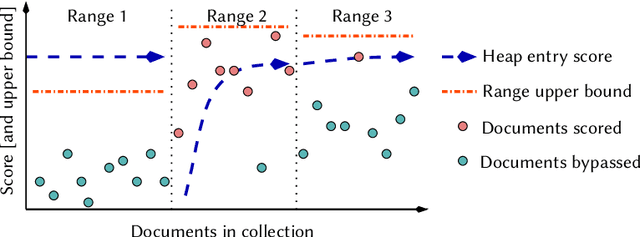


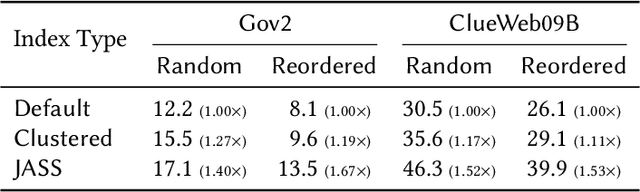
Inverted indexes continue to be a mainstay of text search engines, allowing efficient querying of large document collections. While there are a number of possible organizations, document-ordered indexes are the most common, since they are amenable to various query types, support index updates, and allow for efficient dynamic pruning operations. One disadvantage with document-ordered indexes is that high-scoring documents can be distributed across the document identifier space, meaning that index traversal algorithms that terminate early might put search effectiveness at risk. The alternative is impact-ordered indexes, which primarily support top-k disjunctions, but also allow for anytime query processing, where the search can be terminated at any time, with search quality improving as processing latency increases. Anytime query processing can be used to effectively reduce high-percentile tail latency which is essential for operational scenarios in which a service level agreement (SLA) imposes response time requirements. In this work, we show how document-ordered indexes can be organized such that they can be queried in an anytime fashion, enabling strict latency control with effective early termination. Our experiments show that processing document-ordered topical segments selected by a simple score estimator outperforms existing anytime algorithms, and allows query runtimes to be accurately limited in order to comply with SLA requirements.
Fast, Small and Exact: Infinite-order Language Modelling with Compressed Suffix Trees
Aug 16, 2016Efficient methods for storing and querying are critical for scaling high-order n-gram language models to large corpora. We propose a language model based on compressed suffix trees, a representation that is highly compact and can be easily held in memory, while supporting queries needed in computing language model probabilities on-the-fly. We present several optimisations which improve query runtimes up to 2500x, despite only incurring a modest increase in construction time and memory usage. For large corpora and high Markov orders, our method is highly competitive with the state-of-the-art KenLM package. It imposes much lower memory requirements, often by orders of magnitude, and has runtimes that are either similar (for training) or comparable (for querying).