 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in the Maze: Overcoming Context Limitations in Long-Horizon Agentic Search
Oct 21, 2025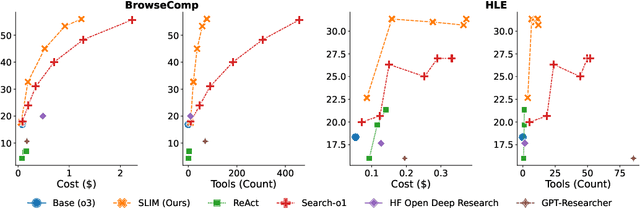



Long-horizon agentic search requires iteratively exploring the web over long trajectories and synthesizing information across many sources, and is the foundation for enabling powerful applications like deep research systems. In this work, we show that popular agentic search frameworks struggle to scale to long trajectories primarily due to context limitations-they accumulate long, noisy content, hit context window and tool budgets, or stop early. Then, we introduce SLIM (Simple Lightweight Information Management), a simple framework that separates retrieval into distinct search and browse tools, and periodically summarizes the trajectory, keeping context concise while enabling longer, more focused searches. On long-horizon tasks, SLIM achieves comparable performance at substantially lower cost and with far fewer tool calls than strong open-source baselines across multiple base models. Specifically, with o3 as the base model, SLIM achieves 56% on BrowseComp and 31% on HLE, outperforming all open-source frameworks by 8 and 4 absolute points, respectively, while incurring 4-6x fewer tool calls. Finally, we release an automated fine-grained trajectory analysis pipeline and error taxonomy for characterizing long-horizon agentic search frameworks; SLIM exhibits fewer hallucinations than prior systems. We hope our analysis framework and simple tool design inform future long-horizon agents.
ColBERT-serve: Efficient Multi-Stage Memory-Mapped Scoring
Apr 21, 2025We study serving retrieval models, specifically late interaction models like ColBERT, to many concurrent users at once and under a small budget, in which the index may not fit in memory. We present ColBERT-serve, a novel serving system that applies a memory-mapping strategy to the ColBERT index, reducing RAM usage by 90% and permitting its deployment on cheap servers, and incorporates a multi-stage architecture with hybrid scoring, reducing ColBERT's query latency and supporting many concurrent queries in parallel.
ALTO: An Efficient Network Orchestrator for Compound AI Systems
Mar 07, 2024We present ALTO, a network orchestrator for efficiently serving compound AI systems such as pipelines of language models. ALTO achieves high throughput and low latency by taking advantage of an optimization opportunity specific to generative language models: streaming intermediate outputs. As language models produce outputs token by token, ALTO exposes opportunities to stream intermediate outputs between stages when possible. We highlight two new challenges of correctness and load balancing which emerge when streaming intermediate data across distributed pipeline stage instances. We also motivate the need for an aggregation-aware routing interface and distributed prompt-aware scheduling to address these challenges. We demonstrate the impact of ALTO's partial output streaming on a complex chatbot verification pipeline, increasing throughput by up to 3x for a fixed latency target of 4 seconds / request while also reducing tail latency by 1.8x compared to a baseline serving approach.