 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocuT5: Seq2seq SQL Generation with Table Documentation
Paper and Code
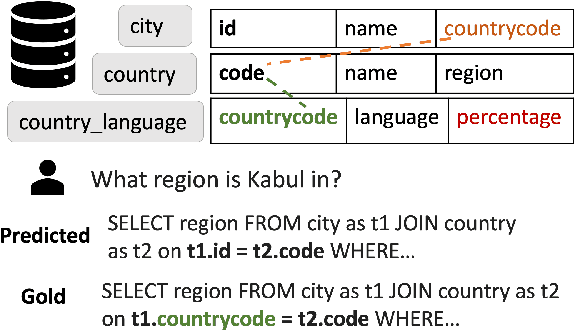



Current SQL generators based on pre-trained language models struggle to answer complex questions requiring domain context or understanding fine-grained table structure. Humans would deal with these unknowns by reasoning over the documentation of the tables. Based on this hypothesis, we propose DocuT5, which uses off-the-shelf language model architecture and injects knowledge from external `documentation' to improve domain generalization. We perform experiments on the Spider family of datasets that contain complex questions that are cross-domain and multi-table. Specifically, we develop a new text-to-SQL failure taxonomy and find that 19.6% of errors are due to foreign key mistakes, and 49.2% are due to a lack of domain knowledge. We proposed DocuT5, a method that captures knowledge from (1) table structure context of foreign keys and (2) domain knowledge through contextualizing tables and columns. Both types of knowledge improve over state-of-the-art T5 with constrained decoding on Spider, and domain knowledge produces state-of-the-art comparable effectiveness on Spider-DK and Spider-SYN datasets.