 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neural Passage Model for Ad-hoc Document Retrieval
Mar 16, 2021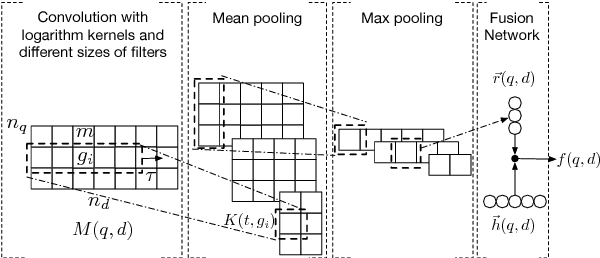
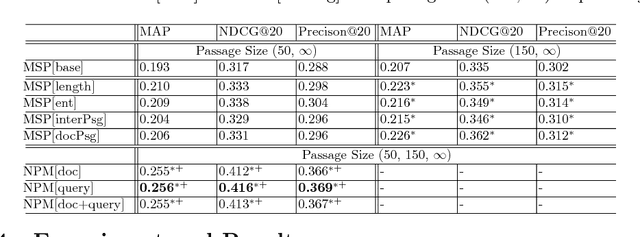
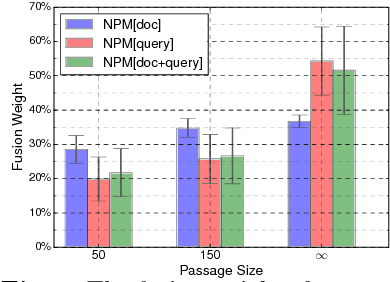
Traditional statistical retrieval models often treat each document as a whole. In many cases, however, a document is relevant to a query only because a small part of it contain the targeted information. In this work, we propose a neural passage model (NPM) that uses passage-level information to improve the performance of ad-hoc retrieval. Instead of using a single window to extract passages, our model automatically learns to weight passages with different granularities in the training process. We show that the passage-based document ranking paradigm from previous studies can be directly derived from our neural framework. Also, our experiments on a TREC collection showed that the NPM can significantly outperform the existing passage-based retrieval models.