 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOT: Self-Supervised Contrastive Pretraining For Zero-Shot Compositional Retrieval
Jan 12, 2025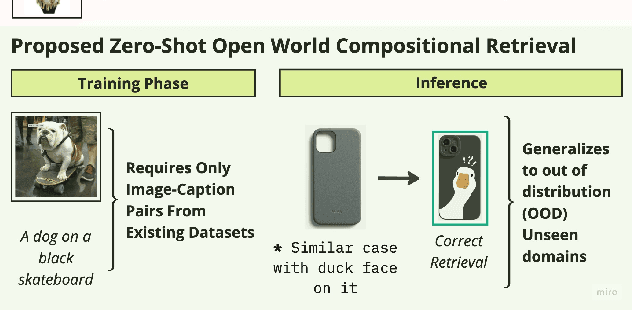
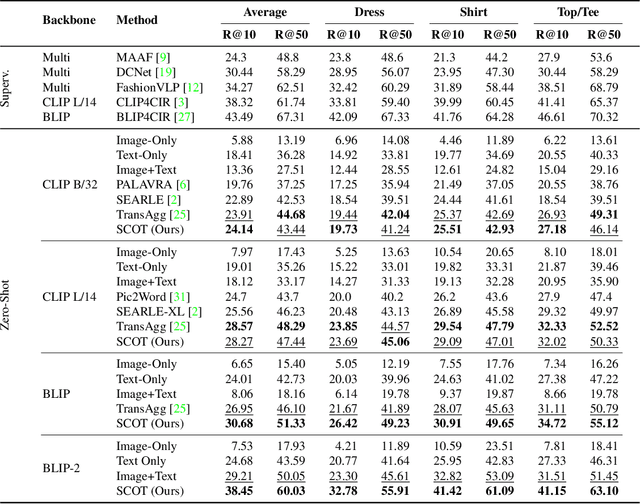
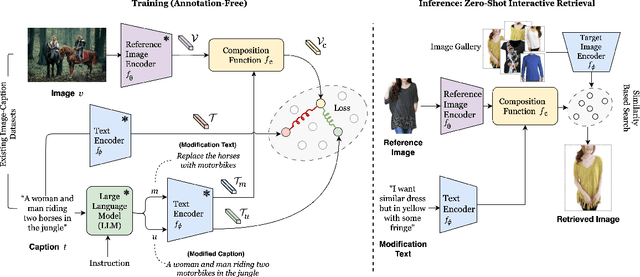
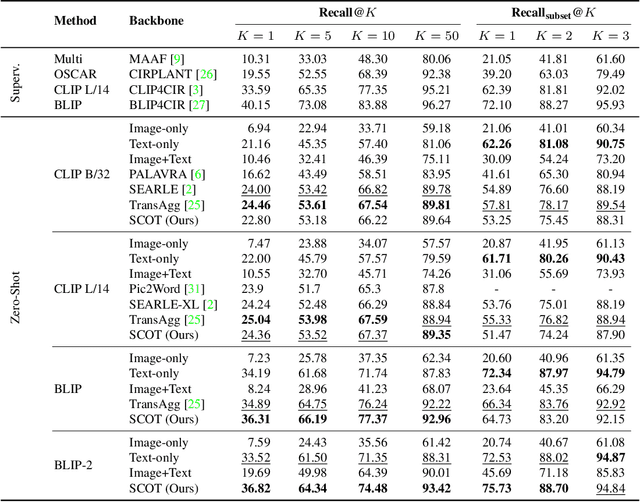
Compositional image retrieval (CIR) is a multimodal learning task where a model combines a query image with a user-provided text modification to retrieve a target image. CIR finds applications in a variety of domains including product retrieval (e-commerce) and web search. Existing methods primarily focus on fully-supervised learning, wherein models are trained on datasets of labeled triplets such as FashionIQ and CIRR. This poses two significant challenges: (i) curating such triplet datasets is labor intensive; and (ii) models lack generalization to unseen objects and domains. In this work, we propose SCOT (Self-supervised COmpositional Training), a novel zero-shot compositional pretraining strategy that combines existing large image-text pair datasets with the generative capabilities of large language models to contrastively train an embedding composition network. Specifically, we show that the text embedding from a large-scale contrastively-pretrained vision-language model can be utilized as proxy target supervision during compositional pretraining, replacing the target image embedding. In zero-shot settings, this strategy surpasses SOTA zero-shot compositional retrieval methods as well as many fully-supervised methods on standard benchmarks such as FashionIQ and CIRR.
CoNAN: Conditional Neural Aggregation Network For Unconstrained Face Feature Fusion
Jul 16, 2023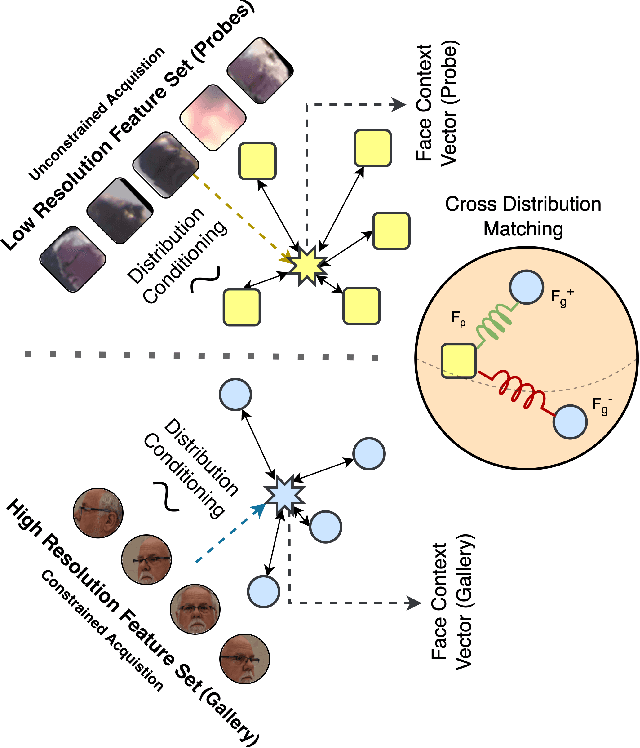
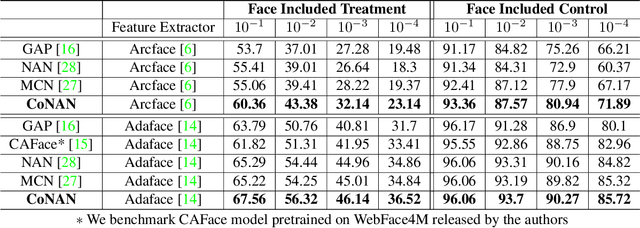
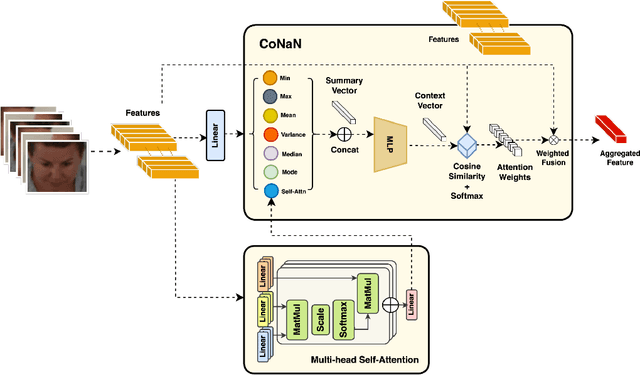
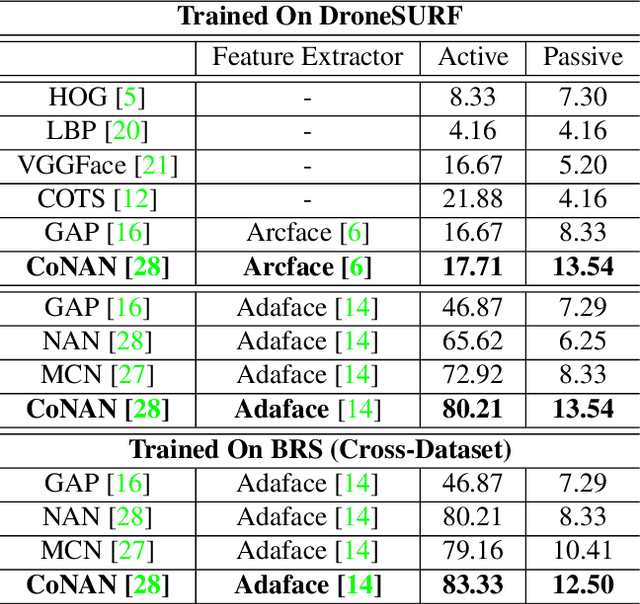
Face recognition from image sets acquired under unregulated and uncontrolled settings, such as at large distances, low resolutions, varying viewpoints, illumination, pose, and atmospheric conditions, is challenging. Face feature aggregation, which involves aggregating a set of N feature representations present in a template into a single global representation, plays a pivotal role in such recognition systems. Existing works in traditional face feature aggregation either utilize metadata or high-dimensional intermediate feature representations to estimate feature quality for aggregation. However, generating high-quality metadata or style information is not feasible for extremely low-resolution faces captured in long-range and high altitude settings. To overcome these limitations, we propose a feature distribution conditioning approach called CoNAN for template aggregation. Specifically, our method aims to learn a context vector conditioned over the distribution information of the incoming feature set, which is utilized to weigh the features based on their estimated informativeness. The proposed method produces state-of-the-art results on long-range unconstrained face recognition datasets such as BTS, and DroneSURF, validating the advantages of such an aggregation strategy.
RidgeBase: A Cross-Sensor Multi-Finger Contactless Fingerprint Dataset
Jul 09, 2023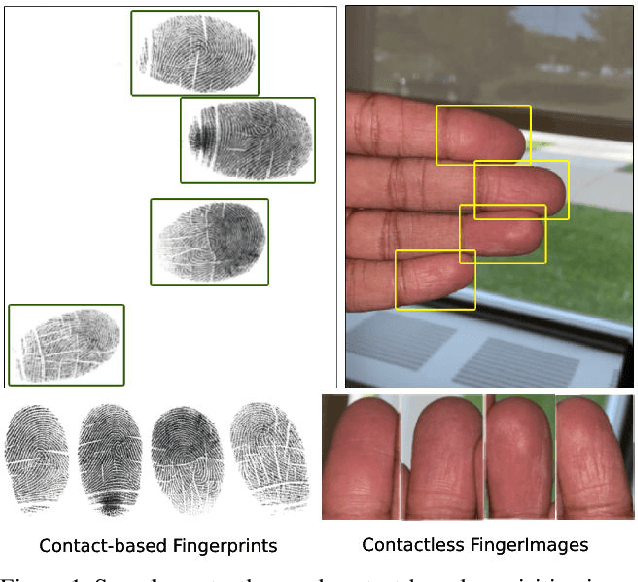


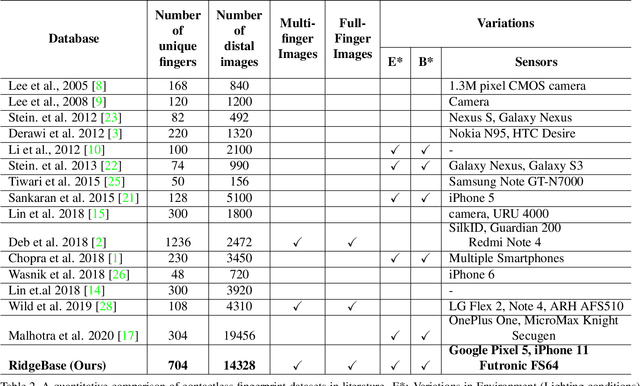
Contactless fingerprint matching using smartphone cameras can alleviate major challenges of traditional fingerprint systems including hygienic acquisition, portability and presentation attacks. However, development of practical and robust contactless fingerprint matching techniques is constrained by the limited availability of large scale real-world datasets. To motivate further advances in contactless fingerprint matching across sensors, we introduce the RidgeBase benchmark dataset. RidgeBase consists of more than 15,000 contactless and contact-based fingerprint image pairs acquired from 88 individuals under different background and lighting conditions using two smartphone cameras and one flatbed contact sensor. Unlike existing datasets, RidgeBase is designed to promote research under different matching scenarios that include Single Finger Matching and Multi-Finger Matching for both contactless- to-contactless (CL2CL) and contact-to-contactless (C2CL) verification and identification. Furthermore, due to the high intra-sample variance in contactless fingerprints belonging to the same finger, we propose a set-based matching protocol inspired by the advances in facial recognition datasets. This protocol is specifically designed for pragmatic contactless fingerprint matching that can account for variances in focus, polarity and finger-angles. We report qualitative and quantitative baseline results for different protocols using a COTS fingerprint matcher (Verifinger) and a Deep CNN based approach on the RidgeBase dataset. The dataset can be downloaded here: https://www.buffalo.edu/cubs/research/datasets/ridgebase-benchmark-dataset.html
* Paper accepted at IJCB 2022
Hear The Flow: Optical Flow-Based Self-Supervised Visual Sound Source Localization
Nov 06, 2022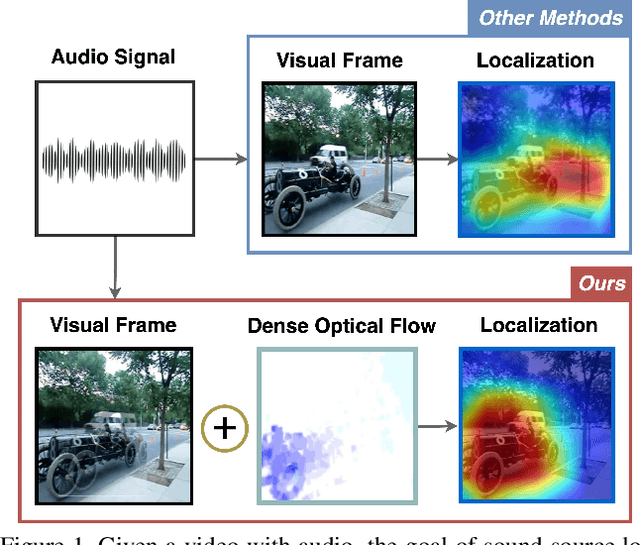
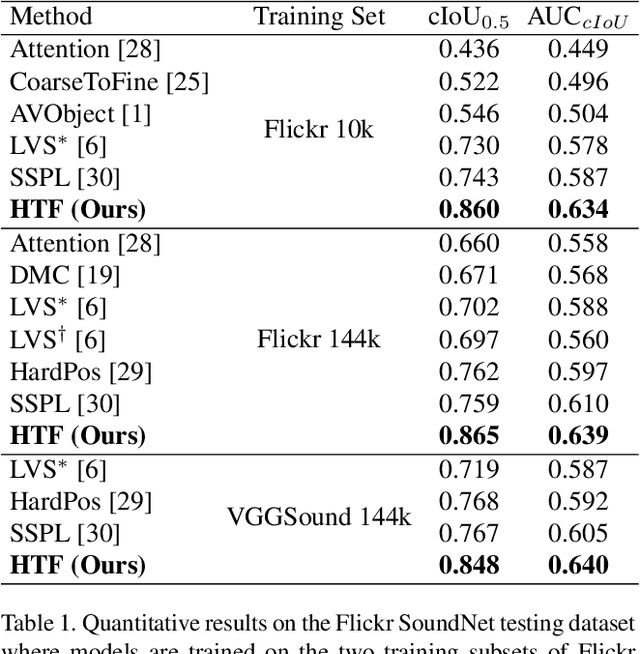
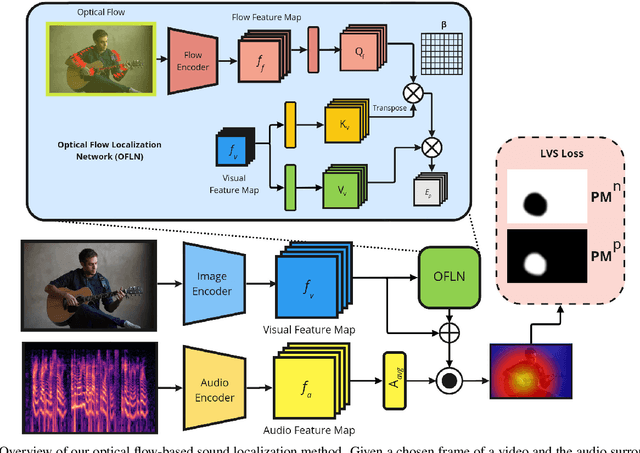
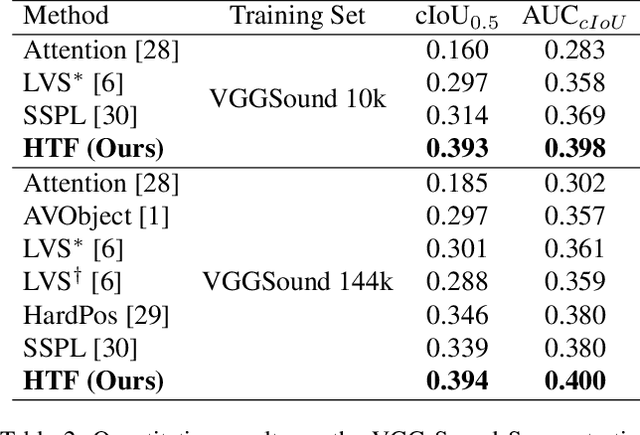
Learning to localize the sound source in videos without explicit annotations is a novel area of audio-visual research. Existing work in this area focuses on creating attention maps to capture the correlation between the two modalities to localize the source of the sound. In a video, oftentimes, the objects exhibiting movement are the ones generating the sound. In this work, we capture this characteristic by modeling the optical flow in a video as a prior to better aid in localizing the sound source. We further demonstrate that the addition of flow-based attention substantially improves visual sound source localization. Finally, we benchmark our method on standard sound source localization datasets and achieve state-of-the-art performance on the Soundnet Flickr and VGG Sound Source datasets. Code: https://github.com/denfed/heartheflow.