 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSboard: Over 3 million characters of ASL fingerspelling collected via smartphones
Jul 22, 2024Progress in machine understanding of sign languages has been slow and hampered by limited data. In this paper, we present FSboard, an American Sign Language fingerspelling dataset situated in a mobile text entry use case, collected from 147 paid and consenting Deaf signers using Pixel 4A selfie cameras in a variety of environments. Fingerspelling recognition is an incomplete solution that is only one small part of sign language translation, but it could provide some immediate benefit to Deaf/Hard of Hearing signers as more broadly capable technology develops. At >3 million characters in length and >250 hours in duration, FSboard is the largest fingerspelling recognition dataset to date by a factor of >10x. As a simple baseline, we finetune 30 Hz MediaPipe Holistic landmark inputs into ByT5-Small and achieve 11.1% Character Error Rate (CER) on a test set with unique phrases and signers. This quality degrades gracefully when decreasing frame rate and excluding face/body landmarks: plausible optimizations to help models run on device in real time.
An Auto Encoder For Audio Dolphin Communication
May 15, 2020
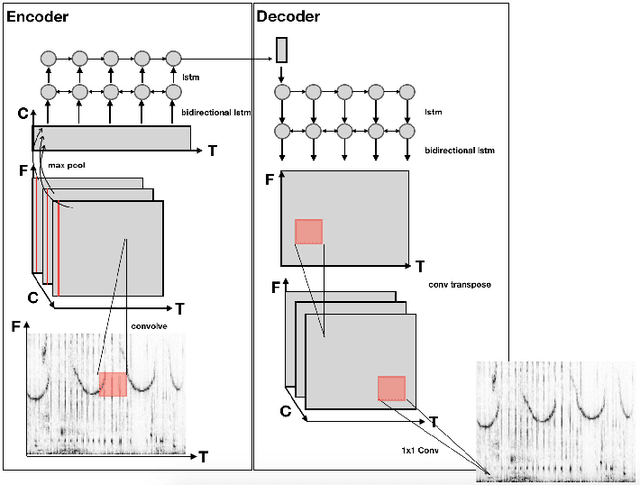


Research in dolphin communication and cognition requires detailed inspection of audible dolphin signals. The manual analysis of these signals is cumbersome and time-consuming. We seek to automate parts of the analysis using modern deep learning methods. We propose to learn an autoencoder constructed from convolutional and recurrent layers trained in an unsupervised fashion. The resulting model embeds patterns in audible dolphin communication. In several experiments, we show that the embeddings can be used for clustering as well as signal detection and signal type classification.
Data-Free Knowledge Distillation for Deep Neural Networks
Nov 23, 2017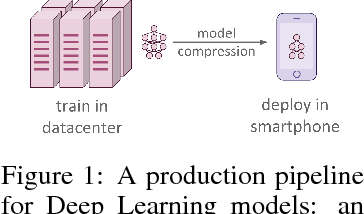
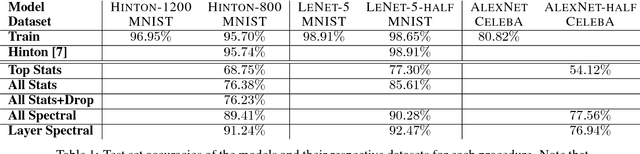


Recent advances in model compression have provided procedures for compressing large neural networks to a fraction of their original size while retaining most if not all of their accuracy. However, all of these approaches rely on access to the original training set, which might not always be possible if the network to be compressed was trained on a very large dataset, or on a dataset whose release poses privacy or safety concerns as may be the case for biometrics tasks. We present a method for data-free knowledge distillation, which is able to compress deep neural networks trained on large-scale datasets to a fraction of their size leveraging only some extra metadata to be provided with a pretrained model release. We also explore different kinds of metadata that can be used with our method, and discuss tradeoffs involved in using each of them.