 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSboard: Over 3 million characters of ASL fingerspelling collected via smartphones
Jul 22, 2024Progress in machine understanding of sign languages has been slow and hampered by limited data. In this paper, we present FSboard, an American Sign Language fingerspelling dataset situated in a mobile text entry use case, collected from 147 paid and consenting Deaf signers using Pixel 4A selfie cameras in a variety of environments. Fingerspelling recognition is an incomplete solution that is only one small part of sign language translation, but it could provide some immediate benefit to Deaf/Hard of Hearing signers as more broadly capable technology develops. At >3 million characters in length and >250 hours in duration, FSboard is the largest fingerspelling recognition dataset to date by a factor of >10x. As a simple baseline, we finetune 30 Hz MediaPipe Holistic landmark inputs into ByT5-Small and achieve 11.1% Character Error Rate (CER) on a test set with unique phrases and signers. This quality degrades gracefully when decreasing frame rate and excluding face/body landmarks: plausible optimizations to help models run on device in real time.
YouTube-ASL: A Large-Scale, Open-Domain American Sign Language-English Parallel Corpus
Jun 27, 2023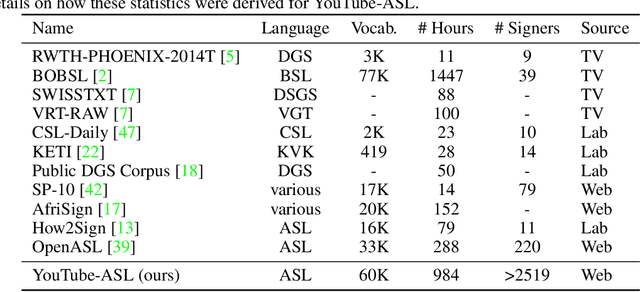
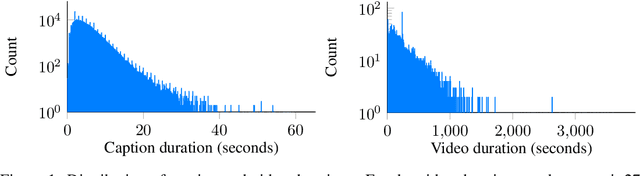

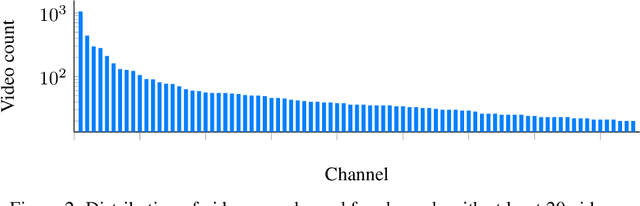
Machine learning for sign languages is bottlenecked by data. In this paper, we present YouTube-ASL, a large-scale, open-domain corpus of American Sign Language (ASL) videos and accompanying English captions drawn from YouTube. With ~1000 hours of videos and >2500 unique signers, YouTube-ASL is ~3x as large and has ~10x as many unique signers as the largest prior ASL dataset. We train baseline models for ASL to English translation on YouTube-ASL and evaluate them on How2Sign, where we achieve a new finetuned state of the art of 12.39 BLEU and, for the first time, report zero-shot results.