 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaWriter: Personalized Handwritten Text Recognition Using Meta-Learned Prompt Tuning
May 26, 2025
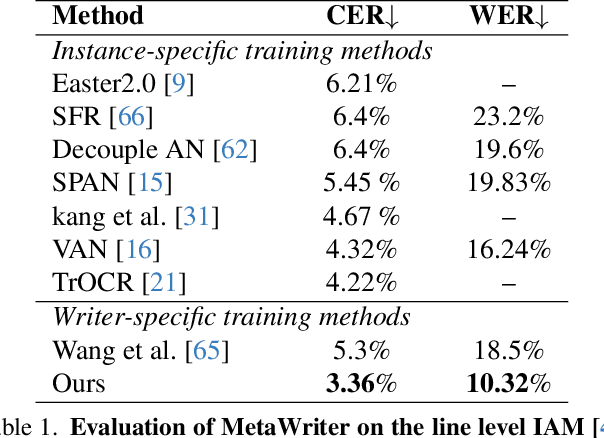
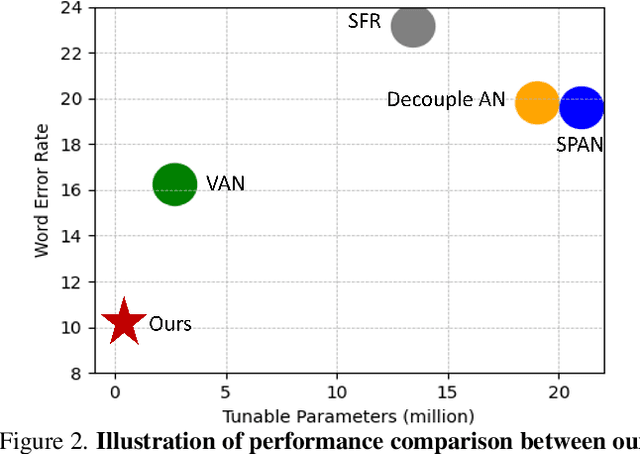

Recent advancements in handwritten text recognition (HTR) have enabled the effective conversion of handwritten text to digital formats. However, achieving robust recognition across diverse writing styles remains challenging. Traditional HTR methods lack writer-specific personalization at test time due to limitations in model architecture and training strategies. Existing attempts to bridge this gap, through gradient-based meta-learning, still require labeled examples and suffer from parameter-inefficient fine-tuning, leading to substantial computational and memory overhead. To overcome these challenges, we propose an efficient framework that formulates personalization as prompt tuning, incorporating an auxiliary image reconstruction task with a self-supervised loss to guide prompt adaptation with unlabeled test-time examples. To ensure self-supervised loss effectively minimizes text recognition error, we leverage meta-learning to learn the optimal initialization of the prompts. As a result, our method allows the model to efficiently capture unique writing styles by updating less than 1% of its parameters and eliminating the need for time-intensive annotation processes. We validate our approach on the RIMES and IAM Handwriting Database benchmarks, where it consistently outperforms previous state-of-the-art methods while using 20x fewer parameters. We believe this represents a significant advancement in personalized handwritten text recognition, paving the way for more reliable and practical deployment in resource-constrained scenarios.
License Plate Detection and Character Recognition Using Deep Learning and Font Evaluation
Dec 17, 2024License plate detection (LPD) is essential for traffic management, vehicle tracking, and law enforcement but faces challenges like variable lighting and diverse font types, impacting accuracy. Traditionally reliant on image processing and machine learning, the field is now shifting towards deep learning for its robust performance in various conditions. Current methods, however, often require tailoring to specific regional datasets. This paper proposes a dual deep learning strategy using a Faster R-CNN for detection and a CNN-RNN model with Connectionist Temporal Classification (CTC) loss and a MobileNet V3 backbone for recognition. This approach aims to improve model performance using datasets from Ontario, Quebec, California, and New York State, achieving a recall rate of 92% on the Centre for Pattern Recognition and Machine Intelligence (CENPARMI) dataset and 90% on the UFPR-ALPR dataset. It includes a detailed error analysis to identify the causes of false positives. Additionally, the research examines the role of font features in license plate (LP) recognition, analyzing fonts like Driver Gothic, Dreadnought, California Clarendon, and Zurich Extra Condensed with the OpenALPR system. It discovers significant performance discrepancies influenced by font characteristics, offering insights for future LPD system enhancements. Keywords: Deep Learning, License Plate, Font Evaluation
* 12 pages, 5 figures. This is the pre-Springer final accepted version. The final version is published in Springer, Lecture Notes in Computer Science (LNCS), Volume 14731, 2024. Springer Version of Record
A Novel Way of Identifying Cyber Predators
Dec 11, 2017



Recurrent Neural Networks with Long Short-Term Memory cell (LSTM-RNN) have impressive ability in sequence data processing, particularly for language model building and text classification. This research proposes the combination of sentiment analysis, new approach of sentence vectors and LSTM-RNN as a novel way for Sexual Predator Identification (SPI). LSTM-RNN language model is applied to generate sentence vectors which are the last hidden states in the language model. Sentence vectors are fed into another LSTM-RNN classifier, so as to capture suspicious conversations. Hidden state enables to generate vectors for sentences never seen before. Fasttext is used to filter the contents of conversations and generate a sentiment score so as to identify potential predators. The experiment achieves a record-breaking accuracy and precision of 100% with recall of 81.10%, exceeding the top-ranked result in the SPI competition.