 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Pedophile Attribution Techniques for Online Platforms
Jan 14, 2025
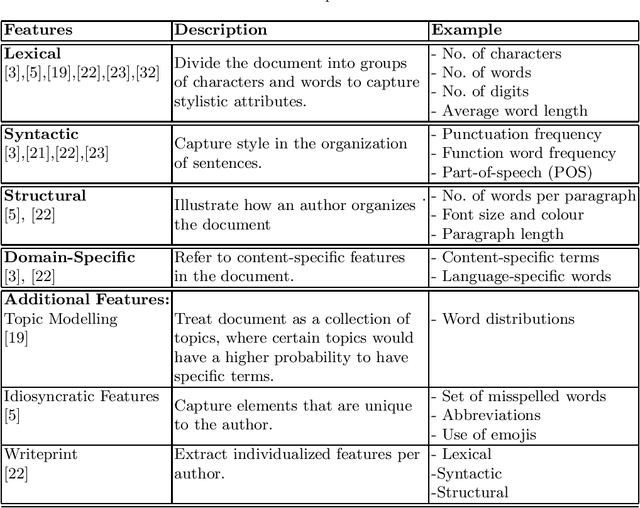
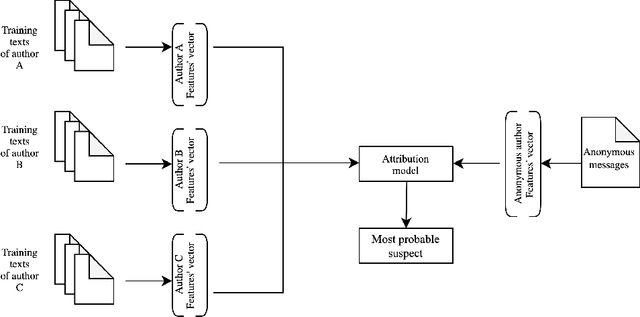
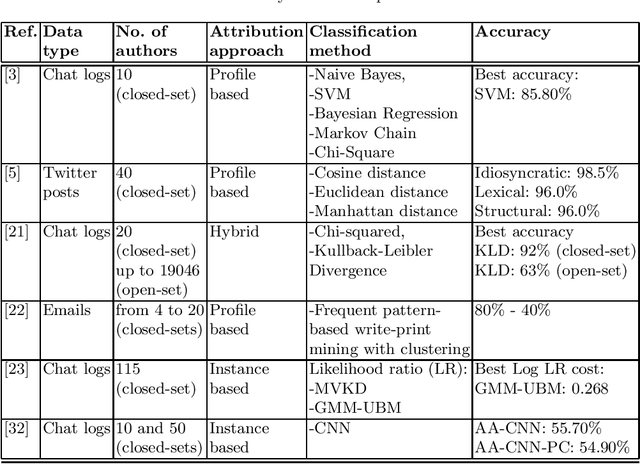
Reliance on anonymity in social media has increased its popularity on these platforms among all ages. The availability of public Wi-Fi networks has facilitated a vast variety of online content, including social media applications. Although anonymity and ease of access can be a convenient means of communication for their users, it is difficult to manage and protect its vulnerable users against sexual predators. Using an automated identification system that can attribute predators to their text would make the solution more attainable. In this survey, we provide a review of the methods of pedophile attribution used in social media platforms. We examine the effect of the size of the suspect set and the length of the text on the task of attribution. Moreover, we review the most-used datasets, features, classification techniques and performance measures for attributing sexual predators. We found that few studies have proposed tools to mitigate the risk of online sexual predators, but none of them can provide suspect attribution. Finally, we list several open research problems.
A Novel Way of Identifying Cyber Predators
Dec 11, 2017



Recurrent Neural Networks with Long Short-Term Memory cell (LSTM-RNN) have impressive ability in sequence data processing, particularly for language model building and text classification. This research proposes the combination of sentiment analysis, new approach of sentence vectors and LSTM-RNN as a novel way for Sexual Predator Identification (SPI). LSTM-RNN language model is applied to generate sentence vectors which are the last hidden states in the language model. Sentence vectors are fed into another LSTM-RNN classifier, so as to capture suspicious conversations. Hidden state enables to generate vectors for sentences never seen before. Fasttext is used to filter the contents of conversations and generate a sentiment score so as to identify potential predators. The experiment achieves a record-breaking accuracy and precision of 100% with recall of 81.10%, exceeding the top-ranked result in the SPI competition.
Managing Requirement Volatility in an Ontology-Driven Clinical LIMS Using Category Theory. International Journal of Telemedicine and Applications
Jun 10, 2009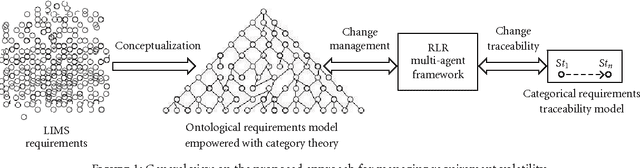
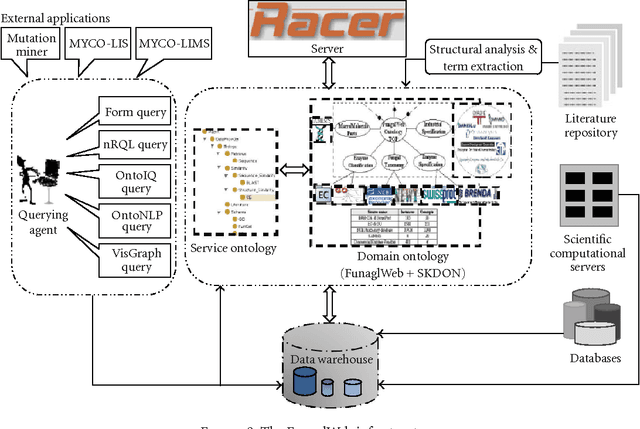
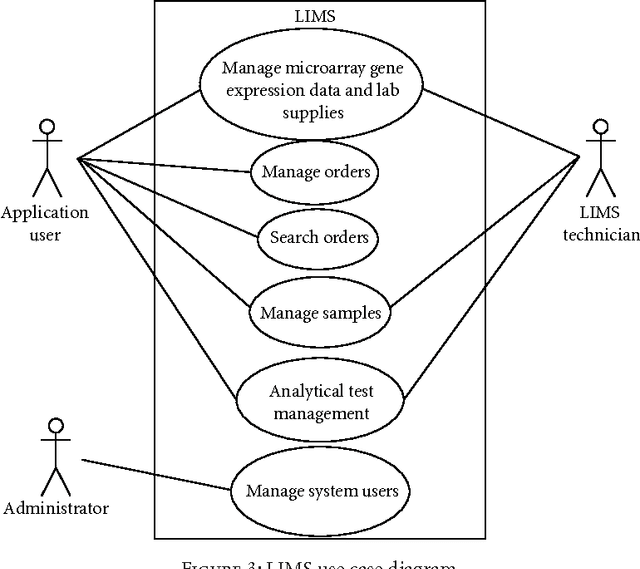
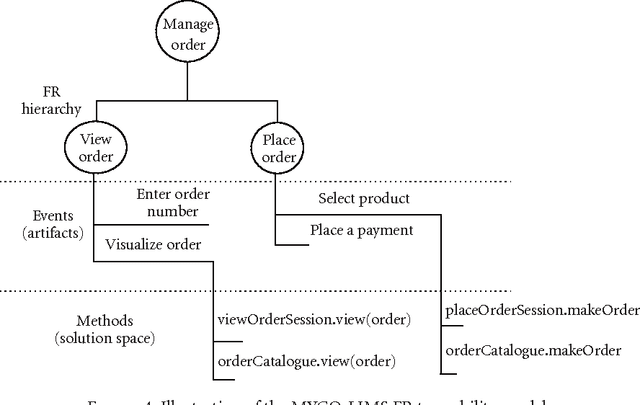
Requirement volatility is an issue in software engineering in general, and in Web-based clinical applications in particular, which often originates from an incomplete knowledge of the domain of interest. With advances in the health science, many features and functionalities need to be added to, or removed from, existing software applications in the biomedical domain. At the same time, the increasing complexity of biomedical systems makes them more difficult to understand, and consequently it is more difficult to define their requirements, which contributes considerably to their volatility. In this paper, we present a novel agent-based approach for analyzing and managing volatile and dynamic requirements in an ontology-driven laboratory information management system (LIMS) designed for Web-based case reporting in medical mycology. The proposed framework is empowered with ontologies and formalized using category theory to provide a deep and common understanding of the functional and nonfunctional requirement hierarchies and their interrelations, and to trace the effects of a change on the conceptual framework.
* 36 Pages, 16 Figures