 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Explainable Learning with Graph Based Data Assessing and Rule Reasoning
Nov 10, 2022


Learning an explainable classifier often results in low accuracy model or ends up with a huge rule set, while learning a deep model is usually more capable of handling noisy data at scale, but with the cost of hard to explain the result and weak at generalization. To mitigate this gap, we propose an end-to-end deep explainable learning approach that combines the advantage of deep model in noise handling and expert rule-based interpretability. Specifically, we propose to learn a deep data assessing model which models the data as a graph to represent the correlations among different observations, whose output will be used to extract key data features. The key features are then fed into a rule network constructed following predefined noisy expert rules with trainable parameters. As these models are correlated, we propose an end-to-end training framework, utilizing the rule classification loss to optimize the rule learning model and data assessing model at the same time. As the rule-based computation is none-differentiable, we propose a gradient linking search module to carry the gradient information from the rule learning model to the data assessing model. The proposed method is tested in an industry production system, showing comparable prediction accuracy, much higher generalization stability and better interpretability when compared with a decent deep ensemble baseline, and shows much better fitting power than pure rule-based approach.
AAformer: Auto-Aligned Transformer for Person Re-Identification
Apr 02, 2021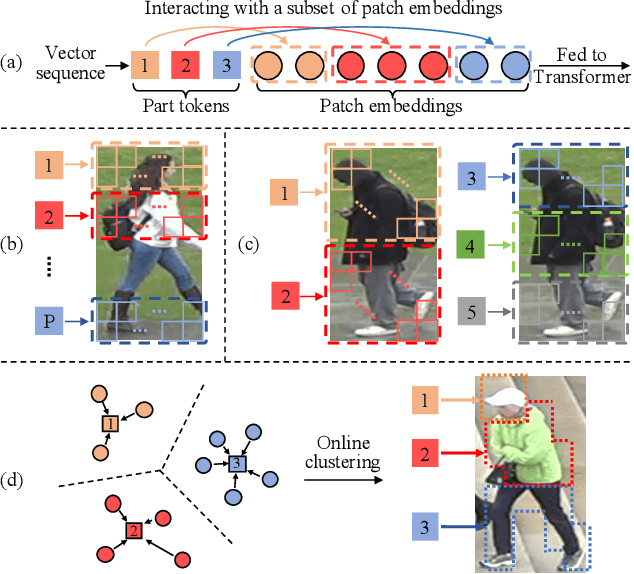
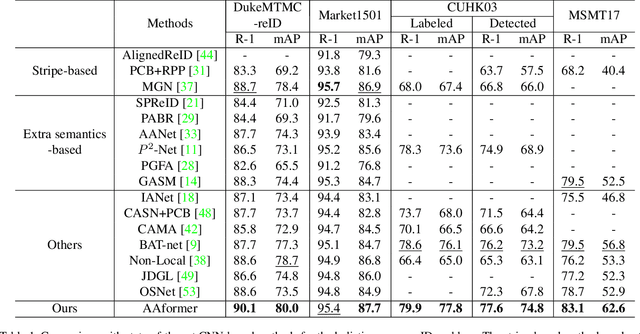
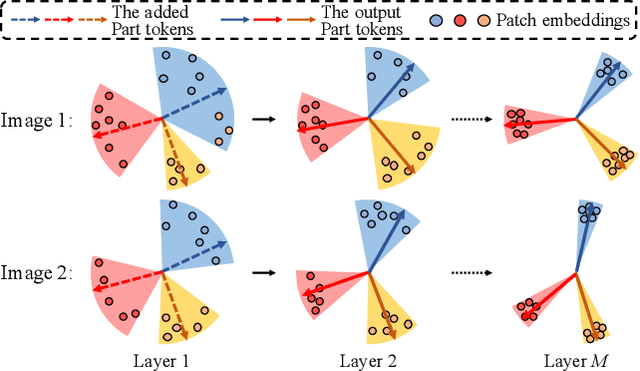
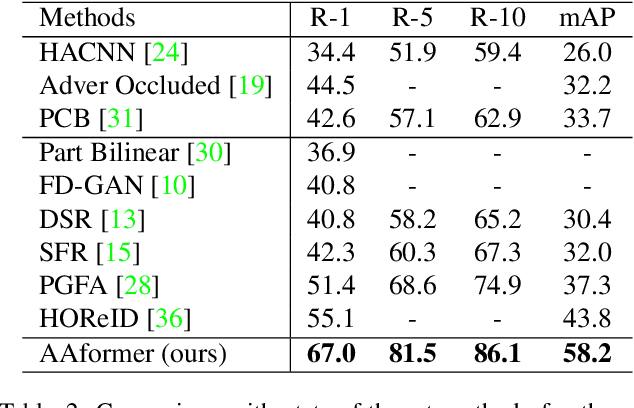
Transformer is showing its superiority over convolutional architectures in many vision tasks like image classification and object detection. However, the lacking of an explicit alignment mechanism limits its capability in person re-identification (re-ID), in which there are inevitable misalignment issues caused by pose/viewpoints variations, etc. On the other hand, the alignment paradigm of convolutional neural networks does not perform well in Transformer in our experiments. To address this problem, we develop a novel alignment framework for Transformer through adding the learnable vectors of "part tokens" to learn the part representations and integrating the part alignment into the self-attention. A part token only interacts with a subset of patch embeddings and learns to represent this subset. Based on the framework, we design an online Auto-Aligned Transformer (AAformer) to adaptively assign the patch embeddings of the same semantics to the identical part token in the running time. The part tokens can be regarded as the part prototypes, and a fast variant of Sinkhorn-Knopp algorithm is employed to cluster the patch embeddings to part tokens online. AAformer can be viewed as a new principled formulation for simultaneously learning both part alignment and part representations. Extensive experiments validate the effectiveness of part tokens and the superiority of AAformer over various state-of-the-art CNN-based methods. Our codes will be released.
Unsupervised Anomaly Detection via Variational Auto-Encoder for Seasonal KPIs in Web Applications
Feb 12, 2018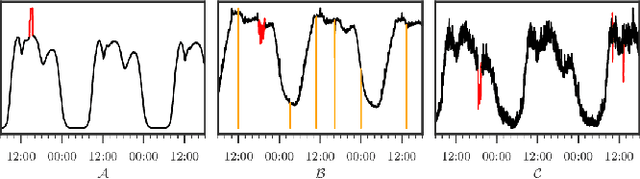

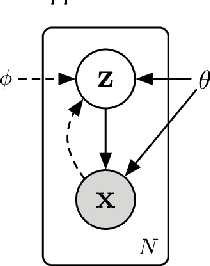

To ensure undisrupted business, large Internet companies need to closely monitor various KPIs (e.g., Page Views, number of online users, and number of orders) of its Web applications, to accurately detect anomalies and trigger timely troubleshooting/mitigation. However, anomaly detection for these seasonal KPIs with various patterns and data quality has been a great challenge, especially without labels. In this paper, we proposed Donut, an unsupervised anomaly detection algorithm based on VAE. Thanks to a few of our key techniques, Donut greatly outperforms a state-of-arts supervised ensemble approach and a baseline VAE approach, and its best F-scores range from 0.75 to 0.9 for the studied KPIs from a top global Internet company. We come up with a novel KDE interpretation of reconstruction for Donut, making it the first VAE-based anomaly detection algorithm with solid theoretical explanation.