 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Graphics Program Generation using Attention-Based Hierarchical Decoder
Oct 26, 2018
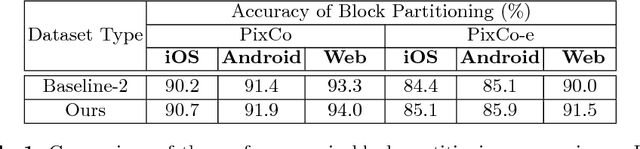

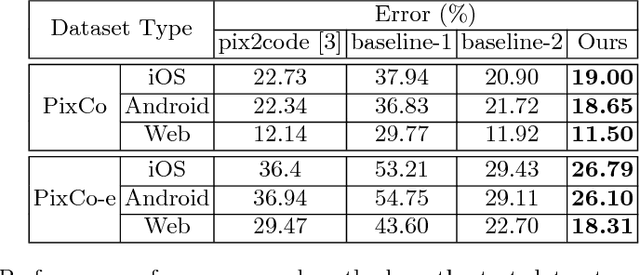
Recent progress on deep learning has made it possible to automatically transform the screenshot of Graphic User Interface (GUI) into code by using the encoder-decoder framework. While the commonly adopted image encoder (e.g., CNN network), might be capable of extracting image features to the desired level, interpreting these abstract image features into hundreds of tokens of code puts a particular challenge on the decoding power of the RNN-based code generator. Considering the code used for describing GUI is usually hierarchically structured, we propose a new attention-based hierarchical code generation model, which can describe GUI images in a finer level of details, while also being able to generate hierarchically structured code in consistency with the hierarchical layout of the graphic elements in the GUI. Our model follows the encoder-decoder framework, all the components of which can be trained jointly in an end-to-end manner. The experimental results show that our method outperforms other current state-of-the-art methods on both a publicly available GUI-code dataset as well as a dataset established by our own.
Topic-Guided Attention for Image Captioning
Jul 10, 2018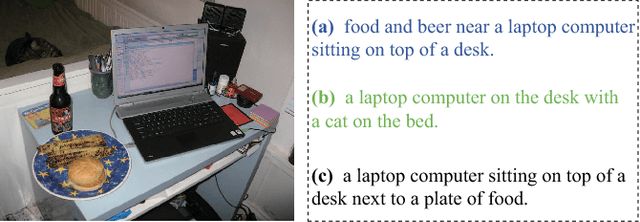
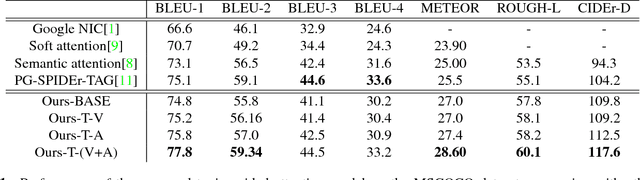
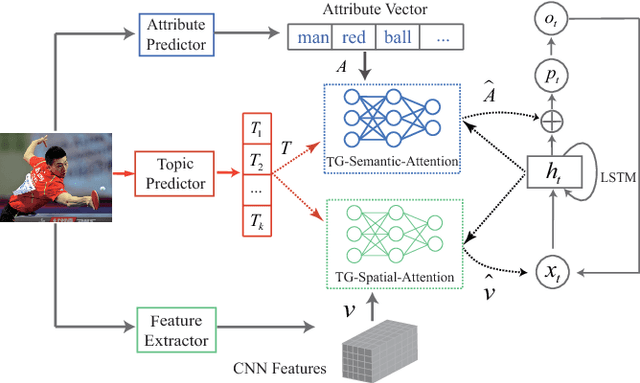

Attention mechanisms have attracted considerable interest in image captioning because of its powerful performance. Existing attention-based models use feedback information from the caption generator as guidance to determine which of the image features should be attended to. A common defect of these attention generation methods is that they lack a higher-level guiding information from the image itself, which sets a limit on selecting the most informative image features. Therefore, in this paper, we propose a novel attention mechanism, called topic-guided attention, which integrates image topics in the attention model as a guiding information to help select the most important image features. Moreover, we extract image features and image topics with separate networks, which can be fine-tuned jointly in an end-to-end manner during training. The experimental results on the benchmark Microsoft COCO dataset show that our method yields state-of-art performance on various quantitative metrics.