 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning for Organs At Risk and Tumor Segmentation with Uncertainty Quantification
May 04, 2023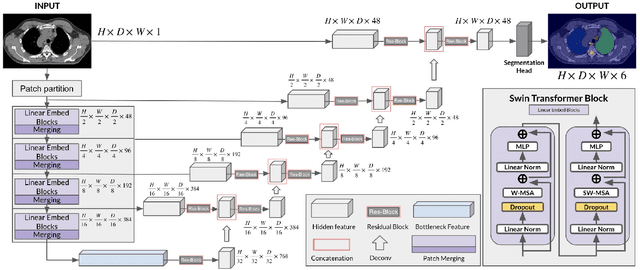
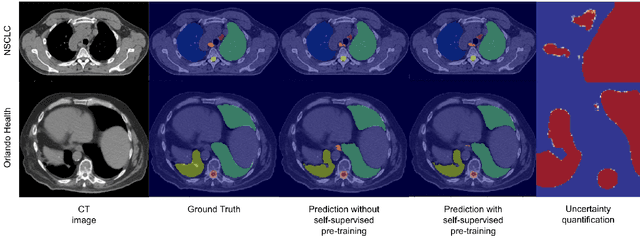
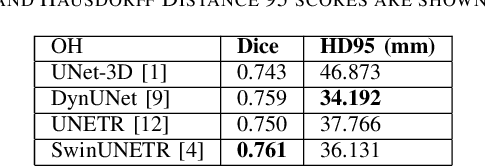
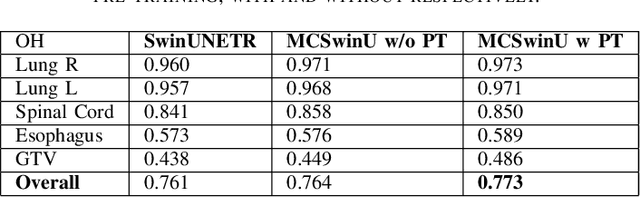
In this study, our goal is to show the impact of self-supervised pre-training of transformers for organ at risk (OAR) and tumor segmentation as compared to costly fully-supervised learning. The proposed algorithm is called Monte Carlo Transformer based U-Net (MC-Swin-U). Unlike many other available models, our approach presents uncertainty quantification with Monte Carlo dropout strategy while generating its voxel-wise prediction. We test and validate the proposed model on both public and one private datasets and evaluate the gross tumor volume (GTV) as well as nearby risky organs' boundaries. We show that self-supervised pre-training approach improves the segmentation scores significantly while providing additional benefits for avoiding large-scale annotation costs.
Enhancing Organ at Risk Segmentation with Improved Deep Neural Networks
Feb 03, 2022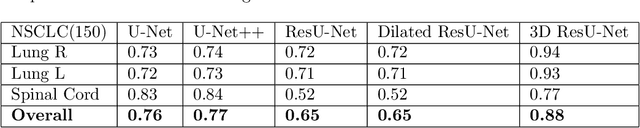
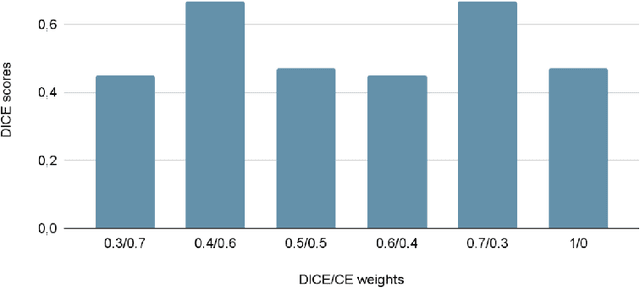
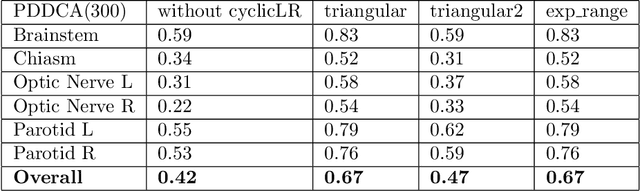
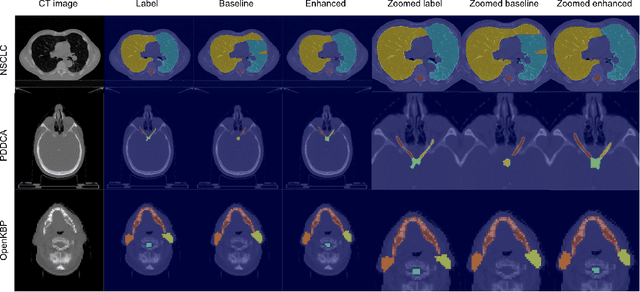
Organ at risk (OAR) segmentation is a crucial step for treatment planning and outcome determination in radiotherapy treatments of cancer patients. Several deep learning based segmentation algorithms have been developed in recent years, however, U-Net remains the de facto algorithm designed specifically for biomedical image segmentation and has spawned many variants with known weaknesses. In this study, our goal is to present simple architectural changes in U-Net to improve its accuracy and generalization properties. Unlike many other available studies evaluating their algorithms on single center data, we thoroughly evaluate several variations of U-Net as well as our proposed enhanced architecture on multiple data sets for an extensive and reliable study of the OAR segmentation problem. Our enhanced segmentation model includes (a)architectural changes in the loss function, (b)optimization framework, and (c)convolution type. Testing on three publicly available multi-object segmentation data sets, we achieved an average of 80% dice score compared to the baseline U-Net performance of 63%.
Facial Expression Recognition Using Human to Animated-Character Expression Translation
Oct 12, 2019

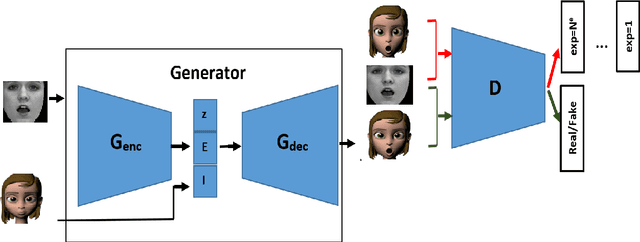

Facial expression recognition is a challenging task due to two major problems: the presence of inter-subject variations in facial expression recognition dataset and impure expressions posed by human subjects. In this paper we present a novel Human-to-Animation conditional Generative Adversarial Network (HA-GAN) to overcome these two problems by using many (human faces) to one (animated face) mapping. Specifically, for any given input human expression image, our HA-GAN transfers the expression information from the input image to a fixed animated identity. Stylized animated characters from the Facial Expression Research Group-Database (FERGDB) are used for the generation of fixed identity. By learning this many-to-one identity mapping function using our proposed HA-GAN, the effect of inter-subject variations can be reduced in Facial Expression Recognition(FER). We also argue that the expressions in the generated animated images are pure expressions and since FER is performed on these generated images, the performance of facial expression recognition is improved. Our initial experimental results on the state-of-the-art datasets show that facial expression recognition carried out on the generated animated images using our HA-GAN framework outperforms the baseline deep neural network and produces comparable or even better results than the state-of-the-art methods for facial expression recognition.