 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRexDrug: Reliable Multi-Drug Combination Extraction through Reasoning-Enhanced LLMs
Mar 09, 2026Automated Drug Combination Extraction (DCE) from large-scale biomedical literature is crucial for advancing precision medicine and pharmacological research. However, existing relation extraction methods primarily focus on binary interactions and struggle to model variable-length n-ary drug combinations, where complex compatibility logic and distributed evidence need to be considered. To address these limitations, we propose RexDrug, an end-to-end reasoning-enhanced relation extraction framework for n-ary drug combination extraction based on large language models. RexDrug adopts a two-stage training strategy. First, a multi-agent collaborative mechanism is utilized to automatically generate high-quality expert-like reasoning traces for supervised fine-tuning. Second, reinforcement learning with a multi-dimensional reward function specifically tailored for DCE is applied to further refine reasoning quality and extraction accuracy. Extensive experiments on the DrugComb dataset show that RexDrug consistently outperforms state-of-the-art baselines for n-ary extraction. Additional evaluation on the DDI13 corpus confirms its generalizability to binary drugdrug interaction tasks. Human expert assessment and automatic reasoning metrics further indicates that RexDrug produces coherent medical reasoning while accurately identifying complex therapeutic regimens. These results establish RexDrug as a scalable and reliable solution for complex biomedical relation extraction from unstructured text. The source code and data are available at https://github.com/DUTIR-BioNLP/RexDrug
A Generalist Foundation Model for Total-body PET/CT Enables Diagnostic Reporting and System-wide Metabolic Profiling
Jan 19, 2026Total-body PET/CT enables system-wide molecular imaging, but heterogeneous anatomical and metabolic signals, approximately 2 m axial coverage, and structured radiology semantics challenge existing medical AI models that assume single-modality inputs, localized fields of view, and coarse image-text alignment. We introduce SDF-HOLO (Systemic Dual-stream Fusion Holo Model), a multimodal foundation model for holistic total-body PET/CT, pre-trained on more than 10,000 patients. SDF-HOLO decouples CT and PET representation learning with dual-stream encoders and couples them through a cross-modal interaction module, allowing anatomical context to refine PET aggregation while metabolic saliency guides subtle morphological reasoning. To model long-range dependencies across the body, hierarchical context modeling combines efficient local windows with global attention. To bridge voxels and clinical language, we use anatomical segmentation masks as explicit semantic anchors and perform voxel-mask-text alignment during pre-training. Across tumor segmentation, low-dose lesion detection, and multilingual diagnostic report generation, SDF-HOLO outperforms strong task-specific and clinical-reference baselines while reducing localization errors and hallucinated findings. Beyond focal interpretation, the model enables system-wide metabolic profiling and reveals tumor-associated fingerprints of inter-organ metabolic network interactions, providing a scalable computational foundation for total-body PET/CT diagnostics and system-level precision oncology.
Overview of CHIP 2025 Shared Task 2: Discharge Medication Recommendation for Metabolic Diseases Based on Chinese Electronic Health Records
Nov 09, 2025Discharge medication recommendation plays a critical role in ensuring treatment continuity, preventing readmission, and improving long-term management for patients with chronic metabolic diseases. This paper present an overview of the CHIP 2025 Shared Task 2 competition, which aimed to develop state-of-the-art approaches for automatically recommending appro-priate discharge medications using real-world Chinese EHR data. For this task, we constructed CDrugRed, a high-quality dataset consisting of 5,894 de-identified hospitalization records from 3,190 patients in China. This task is challenging due to multi-label nature of medication recommendation, het-erogeneous clinical text, and patient-specific variability in treatment plans. A total of 526 teams registered, with 167 and 95 teams submitting valid results to the Phase A and Phase B leaderboards, respectively. The top-performing team achieved the highest overall performance on the final test set, with a Jaccard score of 0.5102, F1 score of 0.6267, demonstrating the potential of advanced large language model (LLM)-based ensemble systems. These re-sults highlight both the promise and remaining challenges of applying LLMs to medication recommendation in Chinese EHRs. The post-evaluation phase remains open at https://tianchi.aliyun.com/competition/entrance/532411/.
MedTrust-RAG: Evidence Verification and Trust Alignment for Biomedical Question Answering
Oct 16, 2025Biomedical question answering (QA) requires accurate interpretation of complex medical knowledge. Large language models (LLMs) have shown promising capabilities in this domain, with retrieval-augmented generation (RAG) systems enhancing performance by incorporating external medical literature. However, RAG-based approaches in biomedical QA suffer from hallucinations due to post-retrieval noise and insufficient verification of retrieved evidence, undermining response reliability. We propose MedTrust-Guided Iterative RAG, a framework designed to enhance factual consistency and mitigate hallucinations in medical QA. Our method introduces three key innovations. First, it enforces citation-aware reasoning by requiring all generated content to be explicitly grounded in retrieved medical documents, with structured Negative Knowledge Assertions used when evidence is insufficient. Second, it employs an iterative retrieval-verification process, where a verification agent assesses evidence adequacy and refines queries through Medical Gap Analysis until reliable information is obtained. Third, it integrates the MedTrust-Align Module (MTAM) that combines verified positive examples with hallucination-aware negative samples, leveraging Direct Preference Optimization to reinforce citation-grounded reasoning while penalizing hallucination-prone response patterns. Experiments on MedMCQA, MedQA, and MMLU-Med demonstrate that our approach consistently outperforms competitive baselines across multiple model architectures, achieving the best average accuracy with gains of 2.7% for LLaMA3.1-8B-Instruct and 2.4% for Qwen3-8B.
CommonVoice-SpeechRE and RPG-MoGe: Advancing Speech Relation Extraction with a New Dataset and Multi-Order Generative Framework
Sep 10, 2025Speech Relation Extraction (SpeechRE) aims to extract relation triplets directly from speech. However, existing benchmark datasets rely heavily on synthetic data, lacking sufficient quantity and diversity of real human speech. Moreover, existing models also suffer from rigid single-order generation templates and weak semantic alignment, substantially limiting their performance. To address these challenges, we introduce CommonVoice-SpeechRE, a large-scale dataset comprising nearly 20,000 real-human speech samples from diverse speakers, establishing a new benchmark for SpeechRE research. Furthermore, we propose the Relation Prompt-Guided Multi-Order Generative Ensemble (RPG-MoGe), a novel framework that features: (1) a multi-order triplet generation ensemble strategy, leveraging data diversity through diverse element orders during both training and inference, and (2) CNN-based latent relation prediction heads that generate explicit relation prompts to guide cross-modal alignment and accurate triplet generation. Experiments show our approach outperforms state-of-the-art methods, providing both a benchmark dataset and an effective solution for real-world SpeechRE. The source code and dataset are publicly available at https://github.com/NingJinzhong/SpeechRE_RPG_MoGe.
STATE ToxiCN: A Benchmark for Span-level Target-Aware Toxicity Extraction in Chinese Hate Speech Detection
Jan 26, 2025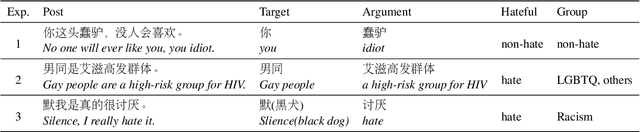
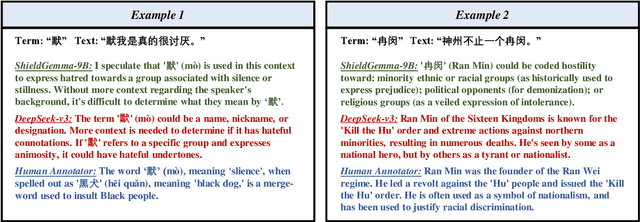
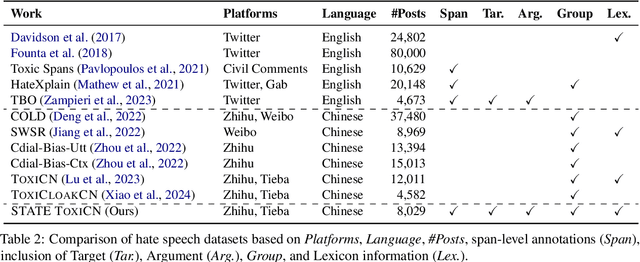

The proliferation of hate speech has caused significant harm to society. The intensity and directionality of hate are closely tied to the target and argument it is associated with. However, research on hate speech detection in Chinese has lagged behind, and existing datasets lack span-level fine-grained annotations. Furthermore, the lack of research on Chinese hateful slang poses a significant challenge. In this paper, we provide a solution for fine-grained detection of Chinese hate speech. First, we construct a dataset containing Target-Argument-Hateful-Group quadruples (STATE ToxiCN), which is the first span-level Chinese hate speech dataset. Secondly, we evaluate the span-level hate speech detection performance of existing models using STATE ToxiCN. Finally, we conduct the first study on Chinese hateful slang and evaluate the ability of LLMs to detect such expressions. Our work contributes valuable resources and insights to advance span-level hate speech detection in Chinese
Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks
Nov 20, 2023



Recent advancements in large language models (LLMs) have shown promising results across a variety of natural language processing (NLP) tasks. The application of LLMs to specific domains, such as biomedicine, has achieved increased attention. However, most biomedical LLMs focus on enhancing performance in monolingual biomedical question answering and conversation tasks. To further investigate the effectiveness of the LLMs on diverse biomedical NLP tasks in different languages, we present Taiyi, a bilingual (English and Chinese) fine-tuned LLM for diverse biomedical tasks. In this work, we first curated a comprehensive collection of 140 existing biomedical text mining datasets across over 10 task types. Subsequently, a two-stage strategy is proposed for supervised fine-tuning to optimize the model performance across varied tasks. Experimental results on 13 test sets covering named entity recognition, relation extraction, text classification, question answering tasks demonstrate Taiyi achieves superior performance compared to general LLMs. The case study involving additional biomedical NLP tasks further shows Taiyi's considerable potential for bilingual biomedical multi-tasking. The source code, datasets, and model for Taiyi are freely available at https://github.com/DUTIR-BioNLP/Taiyi-LLM.