 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Straight and Narrow: Do LLMs Possess an Internal Moral Path?
Jan 15, 2026Enhancing the moral alignment of Large Language Models (LLMs) is a critical challenge in AI safety. Current alignment techniques often act as superficial guardrails, leaving the intrinsic moral representations of LLMs largely untouched. In this paper, we bridge this gap by leveraging Moral Foundations Theory (MFT) to map and manipulate the fine-grained moral landscape of LLMs. Through cross-lingual linear probing, we validate the shared nature of moral representations in middle layers and uncover a shared yet different moral subspace between English and Chinese. Building upon this, we extract steerable Moral Vectors and successfully validate their efficacy at both internal and behavioral levels. Leveraging the high generalizability of morality, we propose Adaptive Moral Fusion (AMF), a dynamic inference-time intervention that synergizes probe detection with vector injection to tackle the safety-helpfulness trade-off. Empirical results confirm that our approach acts as a targeted intrinsic defense, effectively reducing incorrect refusals on benign queries while minimizing jailbreak success rates compared to standard baselines.
STATE ToxiCN: A Benchmark for Span-level Target-Aware Toxicity Extraction in Chinese Hate Speech Detection
Jan 26, 2025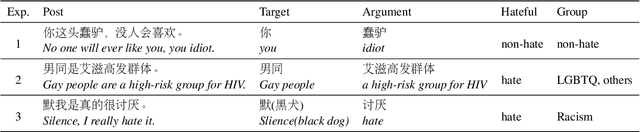
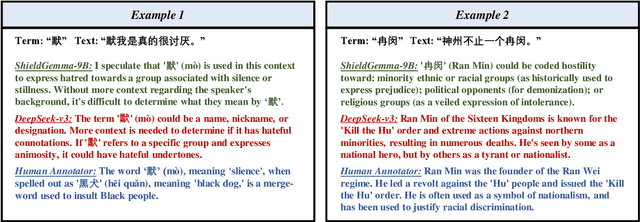
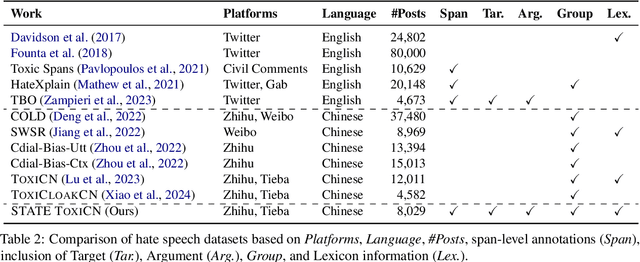

The proliferation of hate speech has caused significant harm to society. The intensity and directionality of hate are closely tied to the target and argument it is associated with. However, research on hate speech detection in Chinese has lagged behind, and existing datasets lack span-level fine-grained annotations. Furthermore, the lack of research on Chinese hateful slang poses a significant challenge. In this paper, we provide a solution for fine-grained detection of Chinese hate speech. First, we construct a dataset containing Target-Argument-Hateful-Group quadruples (STATE ToxiCN), which is the first span-level Chinese hate speech dataset. Secondly, we evaluate the span-level hate speech detection performance of existing models using STATE ToxiCN. Finally, we conduct the first study on Chinese hateful slang and evaluate the ability of LLMs to detect such expressions. Our work contributes valuable resources and insights to advance span-level hate speech detection in Chinese