 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTATE ToxiCN: A Benchmark for Span-level Target-Aware Toxicity Extraction in Chinese Hate Speech Detection
Paper and Code
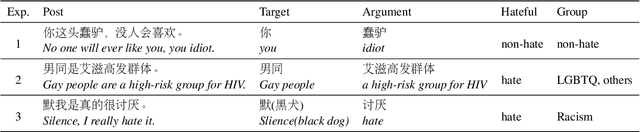
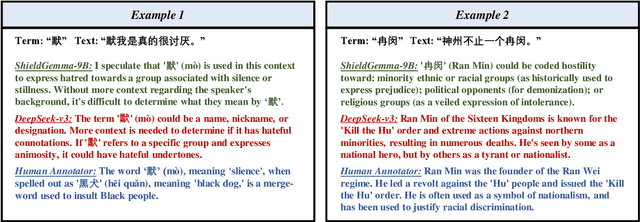
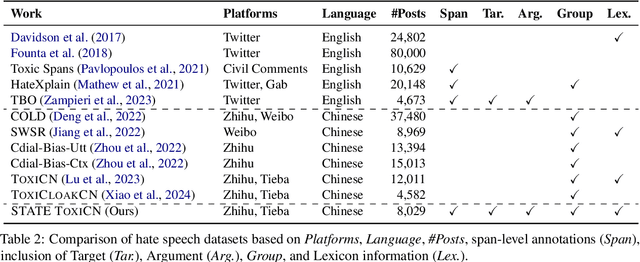

The proliferation of hate speech has caused significant harm to society. The intensity and directionality of hate are closely tied to the target and argument it is associated with. However, research on hate speech detection in Chinese has lagged behind, and existing datasets lack span-level fine-grained annotations. Furthermore, the lack of research on Chinese hateful slang poses a significant challenge. In this paper, we provide a solution for fine-grained detection of Chinese hate speech. First, we construct a dataset containing Target-Argument-Hateful-Group quadruples (STATE ToxiCN), which is the first span-level Chinese hate speech dataset. Secondly, we evaluate the span-level hate speech detection performance of existing models using STATE ToxiCN. Finally, we conduct the first study on Chinese hateful slang and evaluate the ability of LLMs to detect such expressions. Our work contributes valuable resources and insights to advance span-level hate speech detection in Chinese