 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4th Workshop on Maritime Computer Vision (MaCVi): Challenge Overview
Apr 14, 2026The 4th Workshop on Maritime Computer Vision (MaCVi) is organized as part of CVPR 2026. This edition features five benchmark challenges with emphasis on both predictive accuracy and embedded real-time feasibility. This report summarizes the MaCVi 2026 challenge setup, evaluation protocols, datasets, and benchmark tracks, and presents quantitative results, qualitative comparisons, and cross-challenge analyses of emerging method trends. We also include technical reports from top-performing teams to highlight practical design choices and lessons learned across the benchmark suite. Datasets, leaderboards, and challenge resources are available at https://macvi.org/workshop/cvpr26.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
Language-Conditioned Semantic Search-Based Policy for Robotic Manipulation Tasks
Dec 10, 2023



Reinforcement learning and Imitation Learning approaches utilize policy learning strategies that are difficult to generalize well with just a few examples of a task. In this work, we propose a language-conditioned semantic search-based method to produce an online search-based policy from the available demonstration dataset of state-action trajectories. Here we directly acquire actions from the most similar manipulation trajectories found in the dataset. Our approach surpasses the performance of the baselines on the CALVIN benchmark and exhibits strong zero-shot adaptation capabilities. This holds great potential for expanding the use of our online search-based policy approach to tasks typically addressed by Imitation Learning or Reinforcement Learning-based policies.
Faces: AI Blitz XIII Solutions
Apr 03, 2022

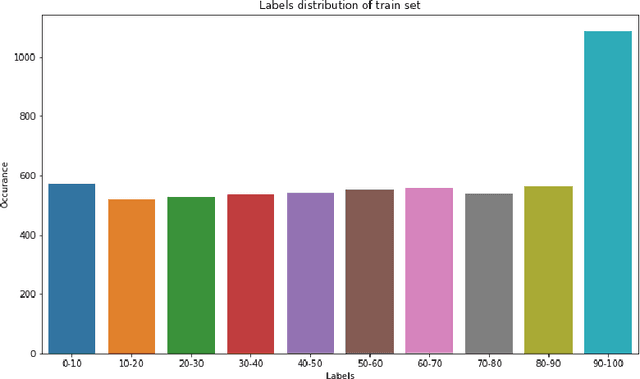

AI Blitz XIII Faces challenge hosted on www.aicrowd.com platform consisted of five problems: Sentiment Classification, Age Prediction, Mask Prediction, Face Recognition, and Face De-Blurring. Our team GLaDOS took second place. Here we present our solutions and results. Code implementation: https://github.com/ndrwmlnk/ai-blitz-xiii