 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy AI-Generated Text Detection Fails: Evidence from Explainable AI Beyond Benchmark Accuracy
Mar 24, 2026The widespread adoption of Large Language Models (LLMs) has made the detection of AI-Generated text a pressing and complex challenge. Although many detection systems report high benchmark accuracy, their reliability in real-world settings remains uncertain, and their interpretability is often unexplored. In this work, we investigate whether contemporary detectors genuinely identify machine authorship or merely exploit dataset-specific artefacts. We propose an interpretable detection framework that integrates linguistic feature engineering, machine learning, and explainable AI techniques. When evaluated on two prominent benchmark corpora, namely PAN CLEF 2025 and COLING 2025, our model trained on 30 linguistic features achieves leaderboard-competitive performance, attaining an F1 score of 0.9734. However, systematic cross-domain and cross-generator evaluation reveals substantial generalisation failure: classifiers that excel in-domain degrade significantly under distribution shift. Using SHAP- based explanations, we show that the most influential features differ markedly between datasets, indicating that detectors often rely on dataset-specific stylistic cues rather than stable signals of machine authorship. Further investigation with in-depth error analysis exposes a fundamental tension in linguistic-feature-based AI text detection: the features that are most discriminative on in-domain data are also the features most susceptible to domain shift, formatting variation, and text-length effects. We believe that this knowledge helps build AI detectors that are robust across different settings. To support replication and practical use, we release an open-source Python package that returns both predictions and instance-level explanations for individual texts.
Multivariate feature ranking of gene expression data
Nov 16, 2021
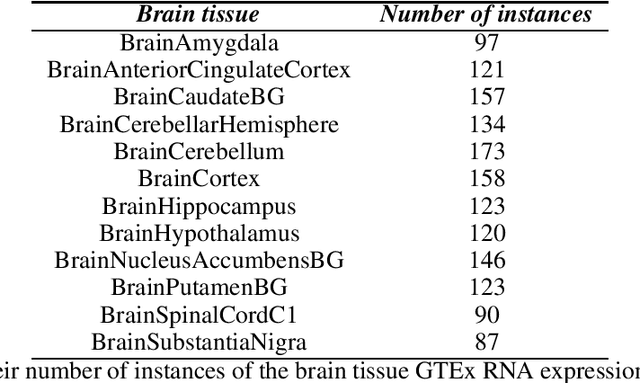


Gene expression datasets are usually of high dimensionality and therefore require efficient and effective methods for identifying the relative importance of their attributes. Due to the huge size of the search space of the possible solutions, the attribute subset evaluation feature selection methods tend to be not applicable, so in these scenarios feature ranking methods are used. Most of the feature ranking methods described in the literature are univariate methods, so they do not detect interactions between factors. In this paper we propose two new multivariate feature ranking methods based on pairwise correlation and pairwise consistency, which we have applied in three gene expression classification problems. We statistically prove that the proposed methods outperform the state of the art feature ranking methods Clustering Variation, Chi Squared, Correlation, Information Gain, ReliefF and Significance, as well as feature selection methods of attribute subset evaluation based on correlation and consistency with multi-objective evolutionary search strategy.
Modelling the COVID-19 virus evolution with Incremental Machine Learning
Apr 21, 2021
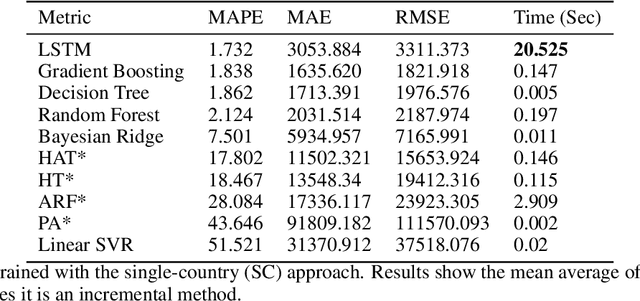

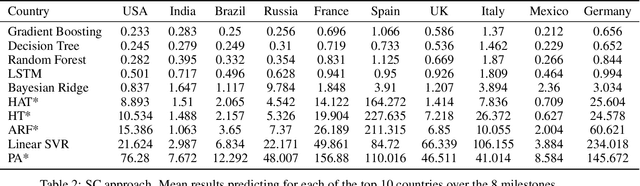
The investment of time and resources for better strategies and methodologies to tackle a potential pandemic is key to deal with potential outbreaks of new variants or other viruses in the future. In this work, we recreated the scene of a year ago, 2020, when the pandemic erupted across the world for the fifty countries with more COVID-19 cases reported. We performed some experiments in which we compare state-of-the-art machine learning algorithms, such as LSTM, against online incremental machine learning algorithms to adapt them to the daily changes in the spread of the disease and predict future COVID-19 cases. To compare the methods, we performed three experiments: In the first one, we trained the models using only data from the country we predicted. In the second one, we use data from all fifty countries to train and predict each of them. In the first and second experiment, we used a static hold-out approach for all methods. In the third experiment, we trained the incremental methods sequentially, using a prequential evaluation. This scheme is not suitable for most state-of-the-art machine learning algorithms because they need to be retrained from scratch for every batch of predictions, causing a computational burden. Results show that incremental methods are a promising approach to adapt to changes of the disease over time; they are always up to date with the last state of the data distribution, and they have a significantly lower computational cost than other techniques such as LSTMs.
A novel auction system for selecting advertisements in Real-Time bidding
Oct 22, 2020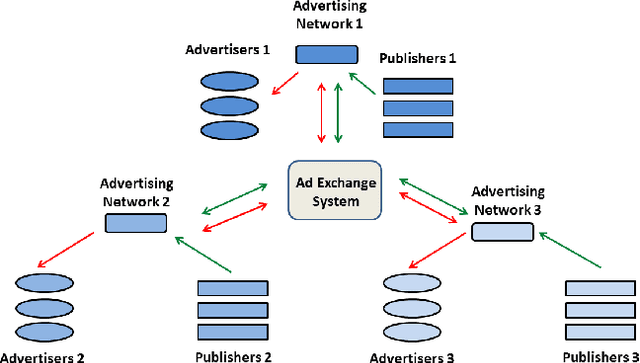

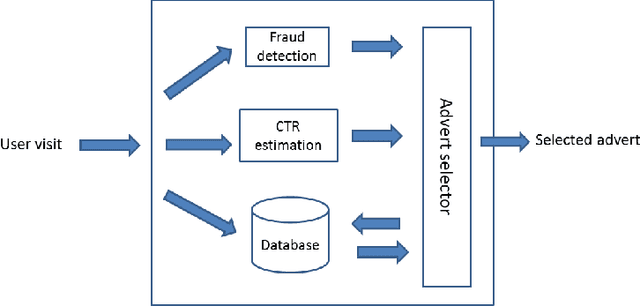
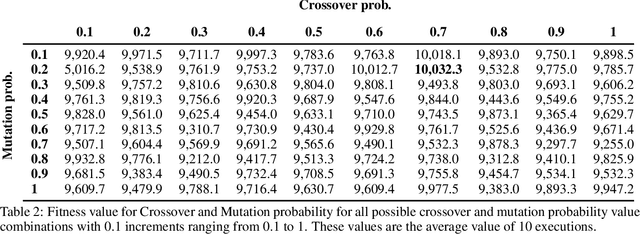
Real-Time Bidding is a new Internet advertising system that has become very popular in recent years. This system works like a global auction where advertisers bid to display their impressions in the publishers' ad slots. The most popular system to select which advertiser wins each auction is the Generalized second-price auction in which the advertiser that offers the most wins the bet and is charged with the price of the second largest bet. In this paper, we propose an alternative betting system with a new approach that not only considers the economic aspect but also other relevant factors for the functioning of the advertising system. The factors that we consider are, among others, the benefit that can be given to each advertiser, the probability of conversion from the advertisement, the probability that the visit is fraudulent, how balanced are the networks participating in RTB and if the advertisers are not paying over the market price. In addition, we propose a methodology based on genetic algorithms to optimize the selection of each advertiser. We also conducted some experiments to compare the performance of the proposed model with the famous Generalized Second-Price method. We think that this new approach, which considers more relevant aspects besides the price, offers greater benefits for RTB networks in the medium and long-term.
A Deep Q-learning/genetic Algorithms Based Novel Methodology For Optimizing Covid-19 Pandemic Government Actions
May 15, 2020

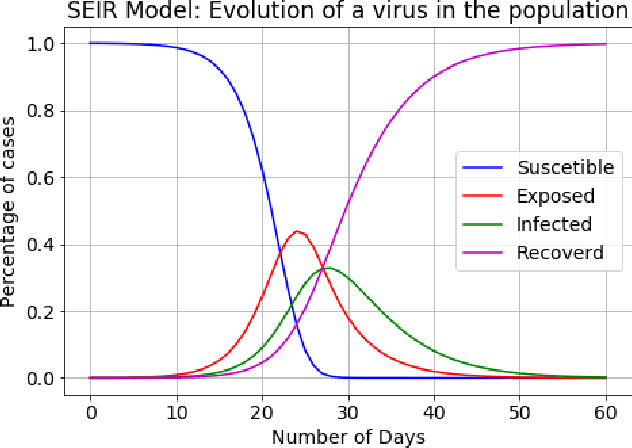

Whenever countries are threatened by a pandemic, as is the case with the COVID-19 virus, governments should take the right actions to safeguard public health as well as to mitigate the negative effects on the economy. In this regard, there are two completely different approaches governments can take: a restrictive one, in which drastic measures such as self-isolation can seriously damage the economy, and a more liberal one, where more relaxed restrictions may put at risk a high percentage of the population. The optimal approach could be somewhere in between, and, in order to make the right decisions, it is necessary to accurately estimate the future effects of taking one or other measures. In this paper, we use the SEIR epidemiological model (Susceptible - Exposed - Infected - Recovered) for infectious diseases to represent the evolution of the virus COVID-19 over time in the population. To optimize the best sequences of actions governments can take, we propose a methodology with two approaches, one based on Deep Q-Learning and another one based on Genetic Algorithms. The sequences of actions (confinement, self-isolation, two-meter distance or not taking restrictions) are evaluated according to a reward system focused on meeting two objectives: firstly, getting few people infected so that hospitals are not overwhelmed with critical patients, and secondly, avoiding taking drastic measures for too long which can potentially cause serious damage to the economy. The conducted experiments prove that our methodology is a valid tool to discover actions governments can take to reduce the negative effects of a pandemic in both senses. We also prove that the approach based on Deep Q-Learning overcomes the one based on Genetic Algorithms for optimizing the sequences of actions.