 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFILM: Framework for Imbalanced Learning Machines based on a new unbiased performance measure and a new ensemble-based technique
Mar 06, 2025



This research addresses the challenges of handling unbalanced datasets for binary classification tasks. In such scenarios, standard evaluation metrics are often biased by the disproportionate representation of the minority class. Conducting experiments across seven datasets, we uncovered inconsistencies in evaluation metrics when determining the model that outperforms others for each binary classification problem. This justifies the need for a metric that provides a more consistent and unbiased evaluation across unbalanced datasets, thereby supporting robust model selection. To mitigate this problem, we propose a novel metric, the Unbiased Integration Coefficients (UIC), which exhibits significantly reduced bias ($p < 10^{-4}$) towards the minority class compared to conventional metrics. The UIC is constructed by aggregating existing metrics while penalising those more prone to imbalance. In addition, we introduce the Identical Partitions for Imbalance Problems (IPIP) algorithm for imbalanced ML problems, an ensemble-based approach. Our experimental results show that IPIP outperforms other baseline imbalance-aware approaches using Random Forest and Logistic Regression models in three out of seven datasets as assessed by the UIC metric, demonstrating its effectiveness in addressing imbalanced data challenges in binary classification tasks. This new framework for dealing with imbalanced datasets is materialized in the FILM (Framework for Imbalanced Learning Machines) R Package, accessible at https://github.com/antoniogt/FILM.
Permutation-based multi-objective evolutionary feature selection for high-dimensional data
Jan 24, 2025Feature selection is a critical step in the analysis of high-dimensional data, where the number of features often vastly exceeds the number of samples. Effective feature selection not only improves model performance and interpretability but also reduces computational costs and mitigates the risk of overfitting. In this context, we propose a novel feature selection method for high-dimensional data, based on the well-known permutation feature importance approach, but extending it to evaluate subsets of attributes rather than individual features. This extension more effectively captures how interactions among features influence model performance. The proposed method employs a multi-objective evolutionary algorithm to search for candidate feature subsets, with the objectives of maximizing the degradation in model performance when the selected features are shuffled, and minimizing the cardinality of the feature subset. The effectiveness of our method has been validated on a set of 24 publicly available high-dimensional datasets for classification and regression tasks, and compared against 9 well-established feature selection methods designed for high-dimensional problems, including the conventional permutation feature importance method. The results demonstrate the ability of our approach in balancing accuracy and computational efficiency, providing a powerful tool for feature selection in complex, high-dimensional datasets.
Embedded feature selection in LSTM networks with multi-objective evolutionary ensemble learning for time series forecasting
Dec 29, 2023Time series forecasting plays a crucial role in diverse fields, necessitating the development of robust models that can effectively handle complex temporal patterns. In this article, we present a novel feature selection method embedded in Long Short-Term Memory networks, leveraging a multi-objective evolutionary algorithm. Our approach optimizes the weights and biases of the LSTM in a partitioned manner, with each objective function of the evolutionary algorithm targeting the root mean square error in a specific data partition. The set of non-dominated forecast models identified by the algorithm is then utilized to construct a meta-model through stacking-based ensemble learning. Furthermore, our proposed method provides an avenue for attribute importance determination, as the frequency of selection for each attribute in the set of non-dominated forecasting models reflects their significance. This attribute importance insight adds an interpretable dimension to the forecasting process. Experimental evaluations on air quality time series data from Italy and southeast Spain demonstrate that our method substantially improves the generalization ability of conventional LSTMs, effectively reducing overfitting. Comparative analyses against state-of-the-art CancelOut and EAR-FS methods highlight the superior performance of our approach.
Multivariate feature ranking of gene expression data
Nov 16, 2021
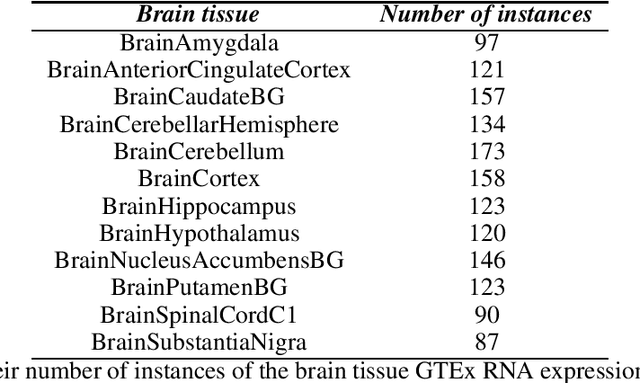


Gene expression datasets are usually of high dimensionality and therefore require efficient and effective methods for identifying the relative importance of their attributes. Due to the huge size of the search space of the possible solutions, the attribute subset evaluation feature selection methods tend to be not applicable, so in these scenarios feature ranking methods are used. Most of the feature ranking methods described in the literature are univariate methods, so they do not detect interactions between factors. In this paper we propose two new multivariate feature ranking methods based on pairwise correlation and pairwise consistency, which we have applied in three gene expression classification problems. We statistically prove that the proposed methods outperform the state of the art feature ranking methods Clustering Variation, Chi Squared, Correlation, Information Gain, ReliefF and Significance, as well as feature selection methods of attribute subset evaluation based on correlation and consistency with multi-objective evolutionary search strategy.