 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Machine Learning for Resource-Constrained Environments
Mar 24, 2025The Internet of Things is an example domain where data is perpetually generated in ever-increasing quantities, reflecting the proliferation of connected devices and the formation of continuous data streams over time. Consequently, the demand for ad-hoc, cost-effective machine learning solutions must adapt to this evolving data influx. This study tackles the task of offloading in small gateways, exacerbated by their dynamic availability over time. An approach leveraging CPU utilization metrics using online and continual machine learning techniques is proposed to predict gateway availability. These methods are compared to popular machine learning algorithms and a recent time-series foundation model, Lag-Llama, for fine-tuned and zero-shot setups. Their performance is benchmarked on a dataset of CPU utilization measurements over time from an IoT gateway and focuses on model metrics such as prediction errors, training and inference times, and memory consumption. Our primary objective is to study new efficient ways to predict CPU performance in IoT environments. Across various scenarios, our findings highlight that ensemble and online methods offer promising results for this task in terms of accuracy while maintaining a low resource footprint.
* 17 pages, 11 figures, accepted at DELTA 2024 (Workshop on Discovering Drift Phenomena in Evolving Landscapes), co-located with ACM SIGKDD 2024. This preprint has not undergone peer review. The Version of Record is available at https://doi.org/10.1007/978-3-031-82346-6_1
Modelling the COVID-19 virus evolution with Incremental Machine Learning
Apr 21, 2021
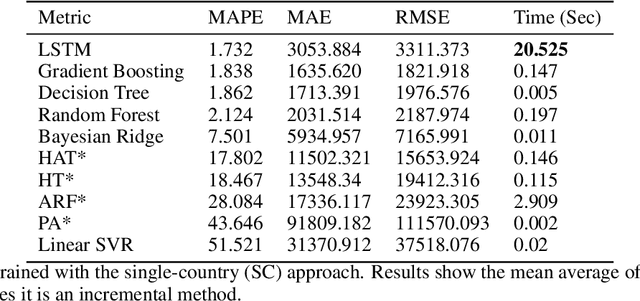

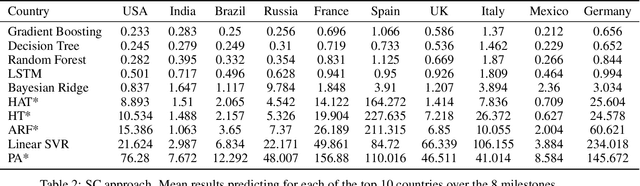
The investment of time and resources for better strategies and methodologies to tackle a potential pandemic is key to deal with potential outbreaks of new variants or other viruses in the future. In this work, we recreated the scene of a year ago, 2020, when the pandemic erupted across the world for the fifty countries with more COVID-19 cases reported. We performed some experiments in which we compare state-of-the-art machine learning algorithms, such as LSTM, against online incremental machine learning algorithms to adapt them to the daily changes in the spread of the disease and predict future COVID-19 cases. To compare the methods, we performed three experiments: In the first one, we trained the models using only data from the country we predicted. In the second one, we use data from all fifty countries to train and predict each of them. In the first and second experiment, we used a static hold-out approach for all methods. In the third experiment, we trained the incremental methods sequentially, using a prequential evaluation. This scheme is not suitable for most state-of-the-art machine learning algorithms because they need to be retrained from scratch for every batch of predictions, causing a computational burden. Results show that incremental methods are a promising approach to adapt to changes of the disease over time; they are always up to date with the last state of the data distribution, and they have a significantly lower computational cost than other techniques such as LSTMs.