 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACTS About Building Retrieval Augmented Generation-based Chatbots
Jul 10, 2024Enterprise chatbots, powered by generative AI, are emerging as key applications to enhance employee productivity. Retrieval Augmented Generation (RAG), Large Language Models (LLMs), and orchestration frameworks like Langchain and Llamaindex are crucial for building these chatbots. However, creating effective enterprise chatbots is challenging and requires meticulous RAG pipeline engineering. This includes fine-tuning embeddings and LLMs, extracting documents from vector databases, rephrasing queries, reranking results, designing prompts, honoring document access controls, providing concise responses, including references, safeguarding personal information, and building orchestration agents. We present a framework for building RAG-based chatbots based on our experience with three NVIDIA chatbots: for IT/HR benefits, financial earnings, and general content. Our contributions are three-fold: introducing the FACTS framework (Freshness, Architectures, Cost, Testing, Security), presenting fifteen RAG pipeline control points, and providing empirical results on accuracy-latency tradeoffs between large and small LLMs. To the best of our knowledge, this is the first paper of its kind that provides a holistic view of the factors as well as solutions for building secure enterprise-grade chatbots."
The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation
Jun 06, 2021
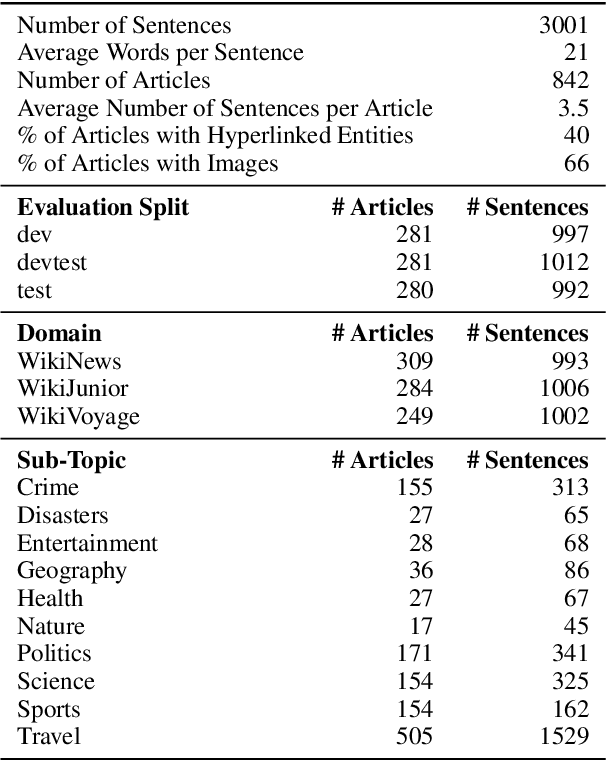


One of the biggest challenges hindering progress in low-resource and multilingual machine translation is the lack of good evaluation benchmarks. Current evaluation benchmarks either lack good coverage of low-resource languages, consider only restricted domains, or are low quality because they are constructed using semi-automatic procedures. In this work, we introduce the FLORES-101 evaluation benchmark, consisting of 3001 sentences extracted from English Wikipedia and covering a variety of different topics and domains. These sentences have been translated in 101 languages by professional translators through a carefully controlled process. The resulting dataset enables better assessment of model quality on the long tail of low-resource languages, including the evaluation of many-to-many multilingual translation systems, as all translations are multilingually aligned. By publicly releasing such a high-quality and high-coverage dataset, we hope to foster progress in the machine translation community and beyond.