Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Representation Distillation with Contrastive Learning
Paper and Code
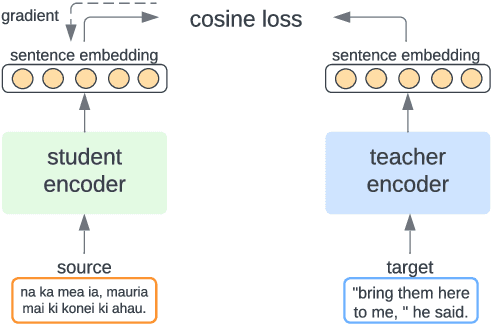

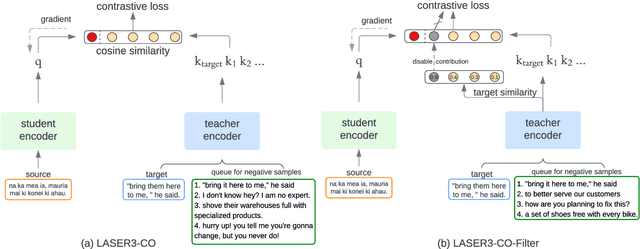
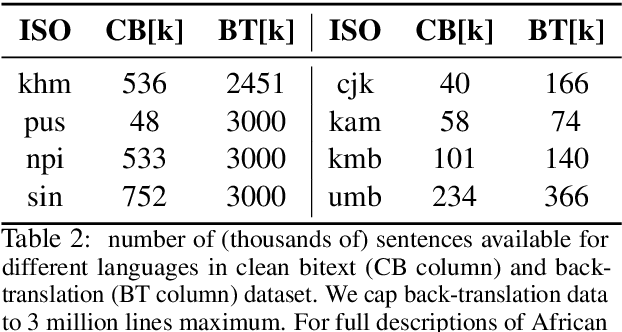
Multilingual sentence representations from large models can encode semantic information from two or more languages and can be used for different cross-lingual information retrieval tasks. In this paper, we integrate contrastive learning into multilingual representation distillation and use it for quality estimation of parallel sentences (find semantically similar sentences that can be used as translations of each other). We validate our approach with multilingual similarity search and corpus filtering tasks. Experiments across different low-resource languages show that our method significantly outperforms previous sentence encoders such as LASER, LASER3, and LaBSE.
View paper on