 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Tune XGBoost with XGBoost
Sep 19, 2019
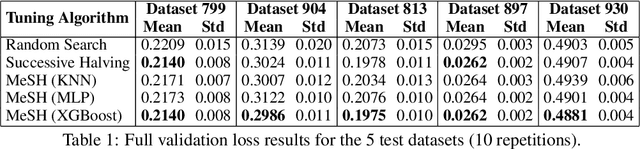

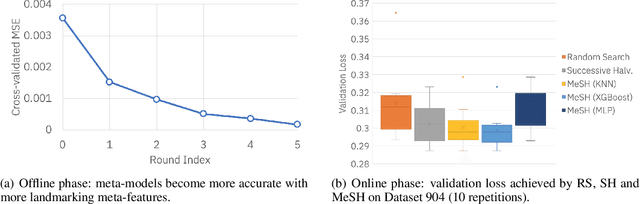
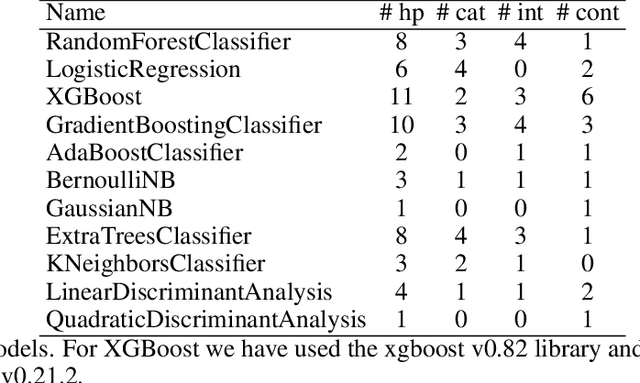
In this short paper we investigate whether meta-learning techniques can be used to more effectively tune the hyperparameters of machine learning models using successive halving (SH). We propose a novel variant of the SH algorithm (MeSH), that uses meta-regressors to determine which candidate configurations should be eliminated at each round. We apply MeSH to the problem of tuning the hyperparameters of a gradient-boosted decision tree model. By training and tuning our meta-regressors using existing tuning jobs from 95 datasets, we demonstrate that MeSH can often find a superior solution to both SH and random search.
Weighted Sampling for Combined Model Selection and Hyperparameter Tuning
Sep 17, 2019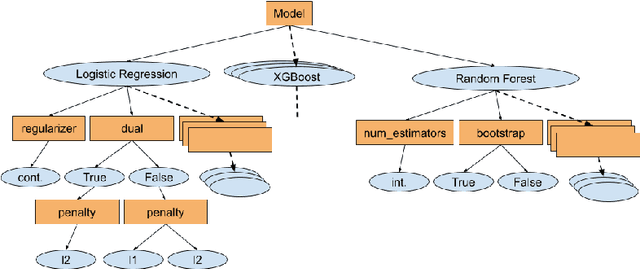
The combined algorithm selection and hyperparameter tuning (CASH) problem is characterized by large hierarchical hyperparameter spaces. Model-free hyperparameter tuning methods can explore such large spaces efficiently since they are highly parallelizable across multiple machines. When no prior knowledge or meta-data exists to boost their performance, these methods commonly sample random configurations following a uniform distribution. In this work, we propose a novel sampling distribution as an alternative to uniform sampling and prove theoretically that it has a better chance of finding the best configuration in a worst-case setting. In order to compare competing methods rigorously in an experimental setting, one must perform statistical hypothesis testing. We show that there is little-to-no agreement in the automated machine learning literature regarding which methods should be used. We contrast this disparity with the methods recommended by the broader statistics literature, and identify the most suitable approach. We then select three popular model-free solutions to CASH and evaluate their performance, with uniform sampling as well as the proposed sampling scheme, across 67 datasets from the OpenML platform. We investigate the trade-off between exploration and exploitation across the three algorithms, and verify empirically that the proposed sampling distribution improves performance in all cases.
Snap ML: A Hierarchical Framework for Machine Learning
Jun 18, 2018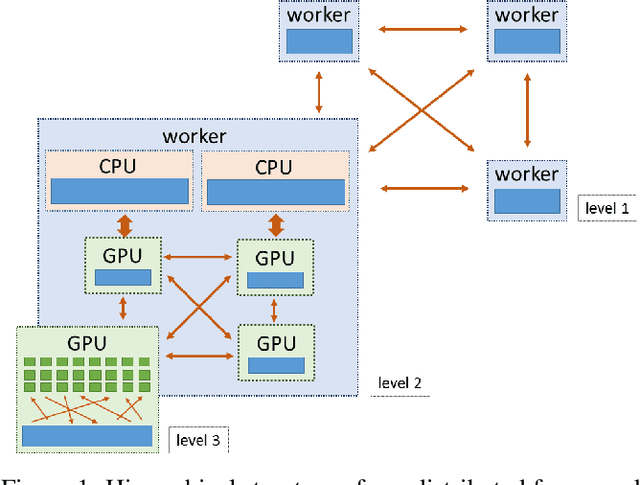

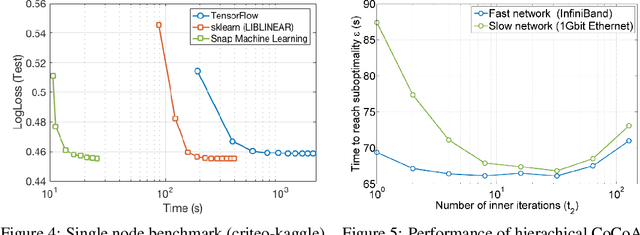
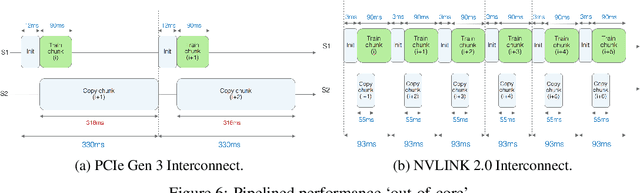
We describe a new software framework for fast training of generalized linear models. The framework, named Snap Machine Learning (Snap ML), combines recent advances in machine learning systems and algorithms in a nested manner to reflect the hierarchical architecture of modern computing systems. We prove theoretically that such a hierarchical system can accelerate training in distributed environments where intra-node communication is cheaper than inter-node communication. Additionally, we provide a review of the implementation of Snap ML in terms of GPU acceleration, pipelining, communication patterns and software architecture, highlighting aspects that were critical for achieving high performance. We evaluate the performance of Snap ML in both single-node and multi-node environments, quantifying the benefit of the hierarchical scheme and the data streaming functionality, and comparing with other widely-used machine learning software frameworks. Finally, we present a logistic regression benchmark on the Criteo Terabyte Click Logs dataset and show that Snap ML achieves the same test loss an order of magnitude faster than any of the previously reported results.