 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePØDA: Prompt-driven Zero-shot Domain Adaptation
Paper and Code
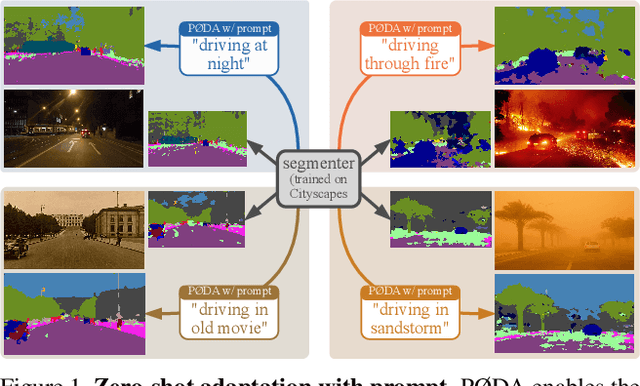


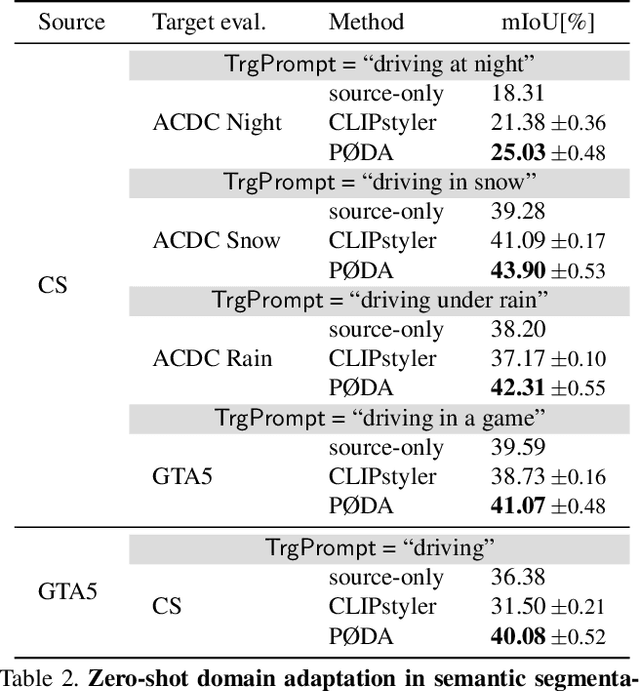
Domain adaptation has been vastly investigated in computer vision but still requires access to target images at train time, which might be intractable in some conditions, especially for long-tail samples. In this paper, we propose the task of `Prompt-driven Zero-shot Domain Adaptation', where we adapt a model trained on a source domain using only a general textual description of the target domain, i.e., a prompt. First, we leverage a pretrained contrastive vision-language model (CLIP) to optimize affine transformations of source features, bringing them closer to target text embeddings, while preserving their content and semantics. Second, we show that augmented features can be used to perform zero-shot domain adaptation for semantic segmentation. Experiments demonstrate that our method significantly outperforms CLIP-based style transfer baselines on several datasets for the downstream task at hand. Our prompt-driven approach even outperforms one-shot unsupervised domain adaptation on some datasets, and gives comparable results on others. The code is available at https://github.com/astra-vision/PODA.