 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Train, all Gain: Self-Supervised Gradients Improve Deep Frozen Representations
Paper and Code

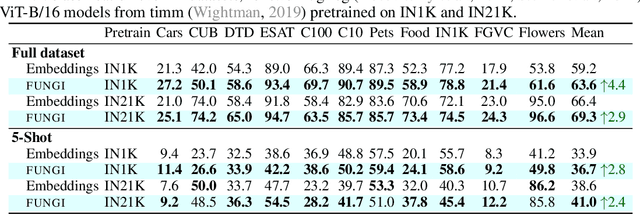

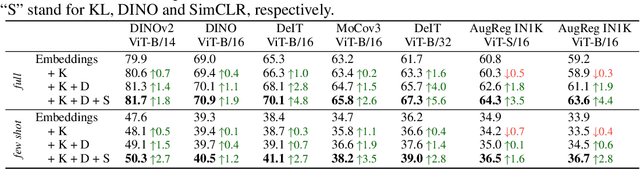
This paper introduces FUNGI, Features from UNsupervised GradIents, a method to enhance the features of vision encoders by leveraging self-supervised gradients. Our method is simple: given any pretrained model, we first compute gradients from various self-supervised objectives for each input. These are projected to a lower dimension and then concatenated with the model's embedding. The resulting features are evaluated on k-nearest neighbor classification over 11 datasets from vision, 5 from natural language processing, and 2 from audio. Across backbones spanning various sizes and pretraining strategies, FUNGI features provide consistent performance improvements over the embeddings. We also show that using FUNGI features can benefit linear classification and image retrieval, and that they significantly improve the retrieval-based in-context scene understanding abilities of pretrained models, for example improving upon DINO by +17% for semantic segmentation - without any training.