 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesim2art: Accurate Articulated Object Modeling from a Single Video using Synthetic Training Data Only
Dec 08, 2025Understanding articulated objects is a fundamental challenge in robotics and digital twin creation. To effectively model such objects, it is essential to recover both part segmentation and the underlying joint parameters. Despite the importance of this task, previous work has largely focused on setups like multi-view systems, object scanning, or static cameras. In this paper, we present the first data-driven approach that jointly predicts part segmentation and joint parameters from monocular video captured with a freely moving camera. Trained solely on synthetic data, our method demonstrates strong generalization to real-world objects, offering a scalable and practical solution for articulated object understanding. Our approach operates directly on casually recorded video, making it suitable for real-time applications in dynamic environments. Project webpage: https://aartykov.github.io/sim2art/
Clustering is back: Reaching state-of-the-art LiDAR instance segmentation without training
Mar 17, 2025Panoptic segmentation of LiDAR point clouds is fundamental to outdoor scene understanding, with autonomous driving being a primary application. While state-of-the-art approaches typically rely on end-to-end deep learning architectures and extensive manual annotations of instances, the significant cost and time investment required for labeling large-scale point cloud datasets remains a major bottleneck in this field. In this work, we demonstrate that competitive panoptic segmentation can be achieved using only semantic labels, with instances predicted without any training or annotations. Our method achieves performance comparable to current state-of-the-art supervised methods on standard benchmarks including SemanticKITTI and nuScenes, and outperforms every publicly available method on SemanticKITTI as a drop-in instance head replacement, while running in real-time on a single-threaded CPU and requiring no instance labels. Our method is fully explainable, and requires no learning or parameter tuning. Code is available at https://github.com/valeoai/Alpine/
UNIT: Unsupervised Online Instance Segmentation through Time
Sep 12, 2024Online object segmentation and tracking in Lidar point clouds enables autonomous agents to understand their surroundings and make safe decisions. Unfortunately, manual annotations for these tasks are prohibitively costly. We tackle this problem with the task of class-agnostic unsupervised online instance segmentation and tracking. To that end, we leverage an instance segmentation backbone and propose a new training recipe that enables the online tracking of objects. Our network is trained on pseudo-labels, eliminating the need for manual annotations. We conduct an evaluation using metrics adapted for temporal instance segmentation. Computing these metrics requires temporally-consistent instance labels. When unavailable, we construct these labels using the available 3D bounding boxes and semantic labels in the dataset. We compare our method against strong baselines and demonstrate its superiority across two different outdoor Lidar datasets.
Revisiting the Distillation of Image Representations into Point Clouds for Autonomous Driving
Oct 26, 2023
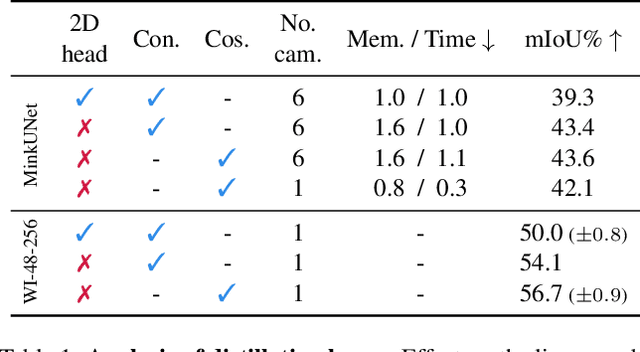
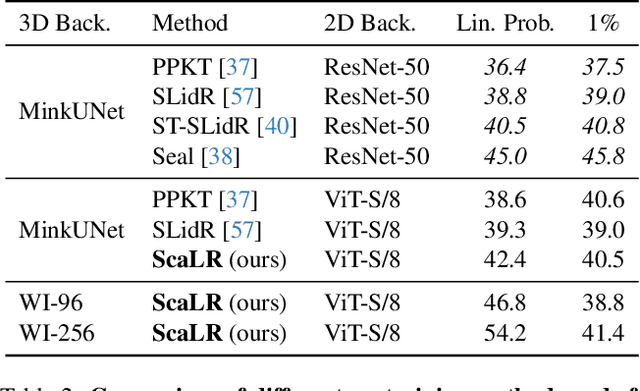
Self-supervised image networks can be used to address complex 2D tasks (e.g., semantic segmentation, object discovery) very efficiently and with little or no downstream supervision. However, self-supervised 3D networks on lidar data do not perform as well for now. A few methods therefore propose to distill high-quality self-supervised 2D features into 3D networks. The most recent ones doing so on autonomous driving data show promising results. Yet, a performance gap persists between these distilled features and fully-supervised ones. In this work, we revisit 2D-to-3D distillation. First, we propose, for semantic segmentation, a simple approach that leads to a significant improvement compared to prior 3D distillation methods. Second, we show that distillation in high capacity 3D networks is key to reach high quality 3D features. This actually allows us to significantly close the gap between unsupervised distilled 3D features and fully-supervised ones. Last, we show that our high-quality distilled representations can also be used for open-vocabulary segmentation and background/foreground discovery.
BEVContrast: Self-Supervision in BEV Space for Automotive Lidar Point Clouds
Oct 26, 2023We present a surprisingly simple and efficient method for self-supervision of 3D backbone on automotive Lidar point clouds. We design a contrastive loss between features of Lidar scans captured in the same scene. Several such approaches have been proposed in the literature from PointConstrast, which uses a contrast at the level of points, to the state-of-the-art TARL, which uses a contrast at the level of segments, roughly corresponding to objects. While the former enjoys a great simplicity of implementation, it is surpassed by the latter, which however requires a costly pre-processing. In BEVContrast, we define our contrast at the level of 2D cells in the Bird's Eye View plane. Resulting cell-level representations offer a good trade-off between the point-level representations exploited in PointContrast and segment-level representations exploited in TARL: we retain the simplicity of PointContrast (cell representations are cheap to compute) while surpassing the performance of TARL in downstream semantic segmentation.
ALSO: Automotive Lidar Self-supervision by Occupancy estimation
Dec 13, 2022



We propose a new self-supervised method for pre-training the backbone of deep perception models operating on point clouds. The core idea is to train the model on a pretext task which is the reconstruction of the surface on which the 3D points are sampled, and to use the underlying latent vectors as input to the perception head. The intuition is that if the network is able to reconstruct the scene surface, given only sparse input points, then it probably also captures some fragments of semantic information, that can be used to boost an actual perception task. This principle has a very simple formulation, which makes it both easy to implement and widely applicable to a large range of 3D sensors and deep networks performing semantic segmentation or object detection. In fact, it supports a single-stream pipeline, as opposed to most contrastive learning approaches, allowing training on limited resources. We conducted extensive experiments on various autonomous driving datasets, involving very different kinds of lidars, for both semantic segmentation and object detection. The results show the effectiveness of our method to learn useful representations without any annotation, compared to existing approaches. Code is available at https://github.com/valeoai/ALSO
Image-to-Lidar Self-Supervised Distillation for Autonomous Driving Data
Mar 30, 2022


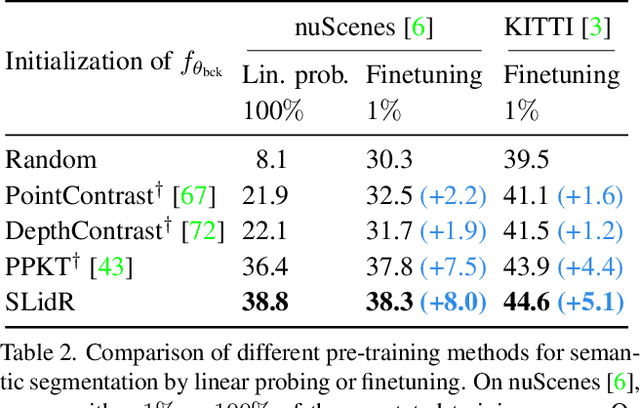
Segmenting or detecting objects in sparse Lidar point clouds are two important tasks in autonomous driving to allow a vehicle to act safely in its 3D environment. The best performing methods in 3D semantic segmentation or object detection rely on a large amount of annotated data. Yet annotating 3D Lidar data for these tasks is tedious and costly. In this context, we propose a self-supervised pre-training method for 3D perception models that is tailored to autonomous driving data. Specifically, we leverage the availability of synchronized and calibrated image and Lidar sensors in autonomous driving setups for distilling self-supervised pre-trained image representations into 3D models. Hence, our method does not require any point cloud nor image annotations. The key ingredient of our method is the use of superpixels which are used to pool 3D point features and 2D pixel features in visually similar regions. We then train a 3D network on the self-supervised task of matching these pooled point features with the corresponding pooled image pixel features. The advantages of contrasting regions obtained by superpixels are that: (1) grouping together pixels and points of visually coherent regions leads to a more meaningful contrastive task that produces features well adapted to 3D semantic segmentation and 3D object detection; (2) all the different regions have the same weight in the contrastive loss regardless of the number of 3D points sampled in these regions; (3) it mitigates the noise produced by incorrect matching of points and pixels due to occlusions between the different sensors. Extensive experiments on autonomous driving datasets demonstrate the ability of our image-to-Lidar distillation strategy to produce 3D representations that transfer well on semantic segmentation and object detection tasks.