 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Distillation of Image Representations into Point Clouds for Autonomous Driving
Paper and Code
Oct 26, 2023
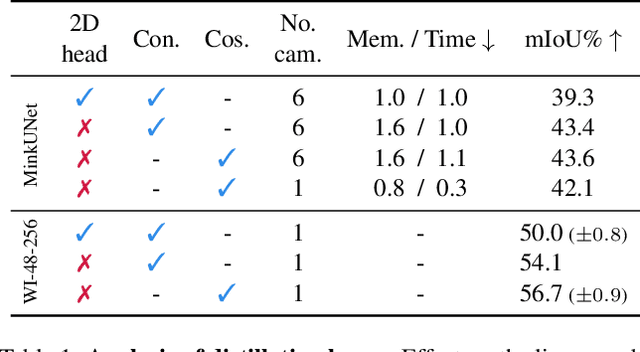
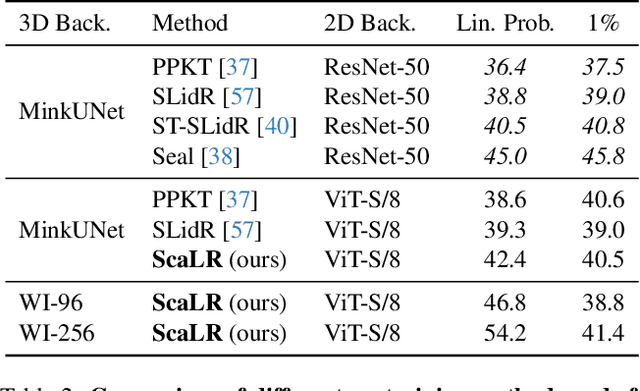
Self-supervised image networks can be used to address complex 2D tasks (e.g., semantic segmentation, object discovery) very efficiently and with little or no downstream supervision. However, self-supervised 3D networks on lidar data do not perform as well for now. A few methods therefore propose to distill high-quality self-supervised 2D features into 3D networks. The most recent ones doing so on autonomous driving data show promising results. Yet, a performance gap persists between these distilled features and fully-supervised ones. In this work, we revisit 2D-to-3D distillation. First, we propose, for semantic segmentation, a simple approach that leads to a significant improvement compared to prior 3D distillation methods. Second, we show that distillation in high capacity 3D networks is key to reach high quality 3D features. This actually allows us to significantly close the gap between unsupervised distilled 3D features and fully-supervised ones. Last, we show that our high-quality distilled representations can also be used for open-vocabulary segmentation and background/foreground discovery.