 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlimmable Encoders for Flexible Split DNNs in Bandwidth and Resource Constrained IoT Systems
Jun 22, 2023



The execution of large deep neural networks (DNN) at mobile edge devices requires considerable consumption of critical resources, such as energy, while imposing demands on hardware capabilities. In approaches based on edge computing the execution of the models is offloaded to a compute-capable device positioned at the edge of 5G infrastructures. The main issue of the latter class of approaches is the need to transport information-rich signals over wireless links with limited and time-varying capacity. The recent split computing paradigm attempts to resolve this impasse by distributing the execution of DNN models across the layers of the systems to reduce the amount of data to be transmitted while imposing minimal computing load on mobile devices. In this context, we propose a novel split computing approach based on slimmable ensemble encoders. The key advantage of our design is the ability to adapt computational load and transmitted data size in real-time with minimal overhead and time. This is in contrast with existing approaches, where the same adaptation requires costly context switching and model loading. Moreover, our model outperforms existing solutions in terms of compression efficacy and execution time, especially in the context of weak mobile devices. We present a comprehensive comparison with the most advanced split computing solutions, as well as an experimental evaluation on GPU-less devices.
Single-Training Collaborative Object Detectors Adaptive to Bandwidth and Computation
May 03, 2021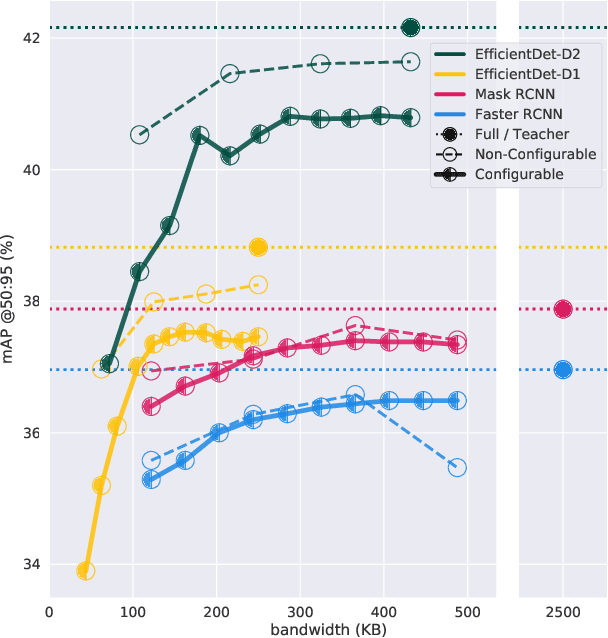
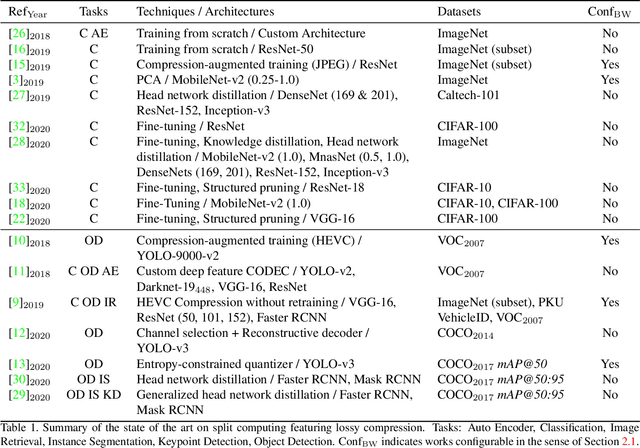
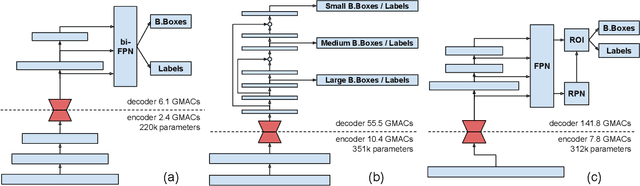

In the past few years, mobile deep-learning deployment progressed by leaps and bounds, but solutions still struggle to accommodate its severe and fluctuating operational restrictions, which include bandwidth, latency, computation, and energy. In this work, we help to bridge that gap, introducing the first configurable solution for object detection that manages the triple communication-computation-accuracy trade-off with a single set of weights. Our solution shows state-of-the-art results on COCO-2017, adding only a minor penalty on the base EfficientDet-D2 architecture. Our design is robust to the choice of base architecture and compressor and should adapt well for future architectures.
Compressing Representations for Embedded Deep Learning
Nov 23, 2019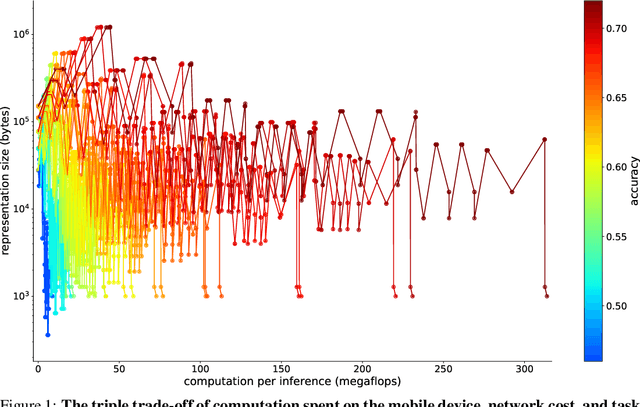
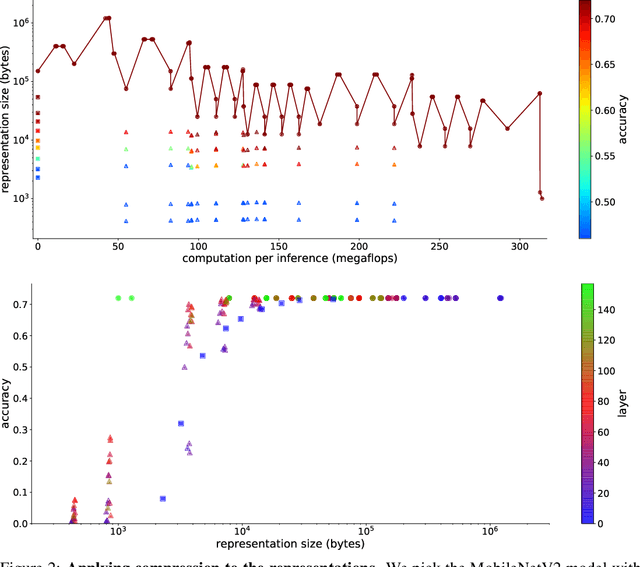
Despite recent advances in architectures for mobile devices, deep learning computational requirements remains prohibitive for most embedded devices. To address that issue, we envision sharing the computational costs of inference between local devices and the cloud, taking advantage of the compression performed by the first layers of the networks to reduce communication costs. Inference in such distributed setting would allow new applications, but requires balancing a triple trade-off between computation cost, communication bandwidth, and model accuracy. We explore that trade-off by studying the compressibility of representations at different stages of MobileNetV2, showing those results agree with theoretical intuitions about deep learning, and that an optimal splitting layer for network can be found with a simple PCA-based compression scheme.