 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenting Customer Support with an NLP-based Receptionist
Dec 03, 2021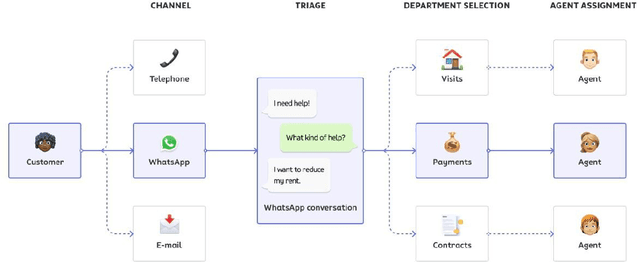

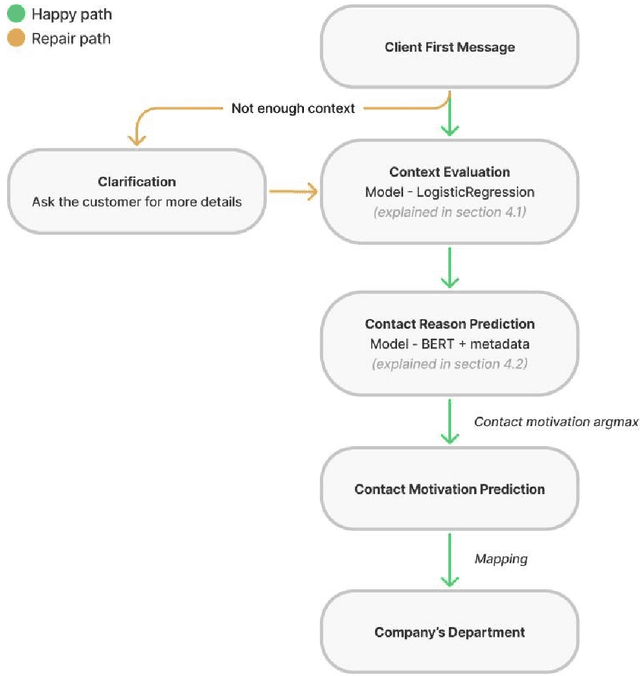

In this paper, we show how a Portuguese BERT model can be combined with structured data in order to deploy a chatbot based on a finite state machine to create a conversational AI system that helps a real-estate company to predict its client's contact motivation. The model achieves human level results in a dataset that contains 235 unbalanced labels. Then, we also show its benefits considering the business impact comparing it against classical NLP methods.
* 11 pages, 2 figures, Symposium in Information and Human Language Technology (STIL)
Compressing Representations for Embedded Deep Learning
Nov 23, 2019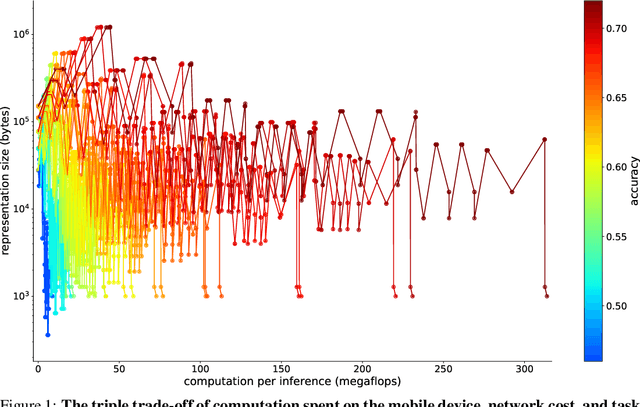
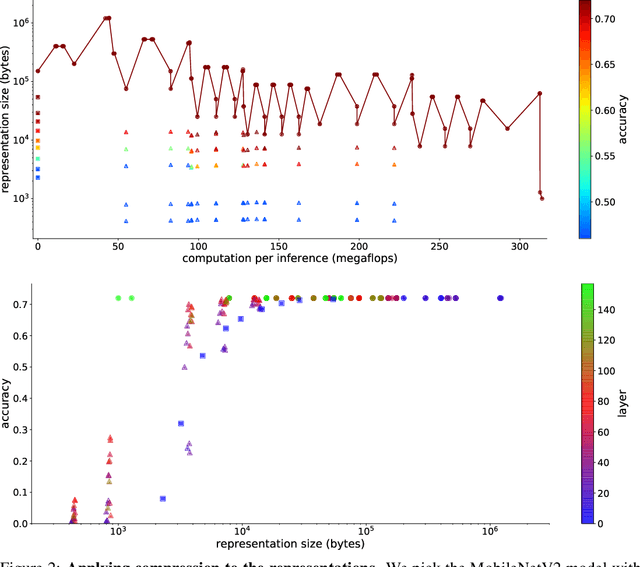
Despite recent advances in architectures for mobile devices, deep learning computational requirements remains prohibitive for most embedded devices. To address that issue, we envision sharing the computational costs of inference between local devices and the cloud, taking advantage of the compression performed by the first layers of the networks to reduce communication costs. Inference in such distributed setting would allow new applications, but requires balancing a triple trade-off between computation cost, communication bandwidth, and model accuracy. We explore that trade-off by studying the compressibility of representations at different stages of MobileNetV2, showing those results agree with theoretical intuitions about deep learning, and that an optimal splitting layer for network can be found with a simple PCA-based compression scheme.
Pay Voice: Point of Sale Recognition for Visually Impaired People
Dec 14, 2018



Millions of visually impaired people depend on relatives and friends to perform their everyday tasks. One relevant step towards self-sufficiency is to provide them with means to verify the value and operation presented in payment machines. In this work, we developed and released a smartphone application, named Pay Voice, that uses image processing, optical character recognition (OCR) and voice synthesis to recognize the value and operation presented in POS and PIN pad machines, and thus informing the user with auditive and visual feedback. The proposed approach presented significant results for value and operation recognition, especially for POS, due to the higher display quality. Importantly, we achieved the key performance indicators, namely, more than 80% of accuracy in a real-world scenario, and less than $5$ seconds of processing time for recognition. Pay Voice is publicly available on Google Play and App Store for free.
Cross-Domain Face Verification: Matching ID Document and Self-Portrait Photographs
Nov 17, 2016
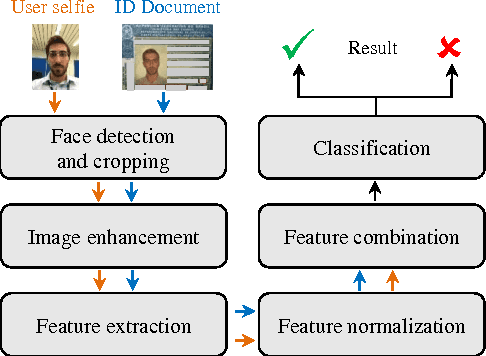


Cross-domain biometrics has been emerging as a new necessity, which poses several additional challenges, including harsh illumination changes, noise, pose variation, among others. In this paper, we explore approaches to cross-domain face verification, comparing self-portrait photographs ("selfies") to ID documents. We approach the problem with proper image photometric adjustment and data standardization techniques, along with deep learning methods to extract the most prominent features from the data, reducing the effects of domain shift in this problem. We validate the methods using a novel dataset comprising 50 individuals. The obtained results are promising and indicate that the adopted path is worth further investigation.
Using Deep Learning for Detecting Spoofing Attacks on Speech Signals
Jan 19, 2016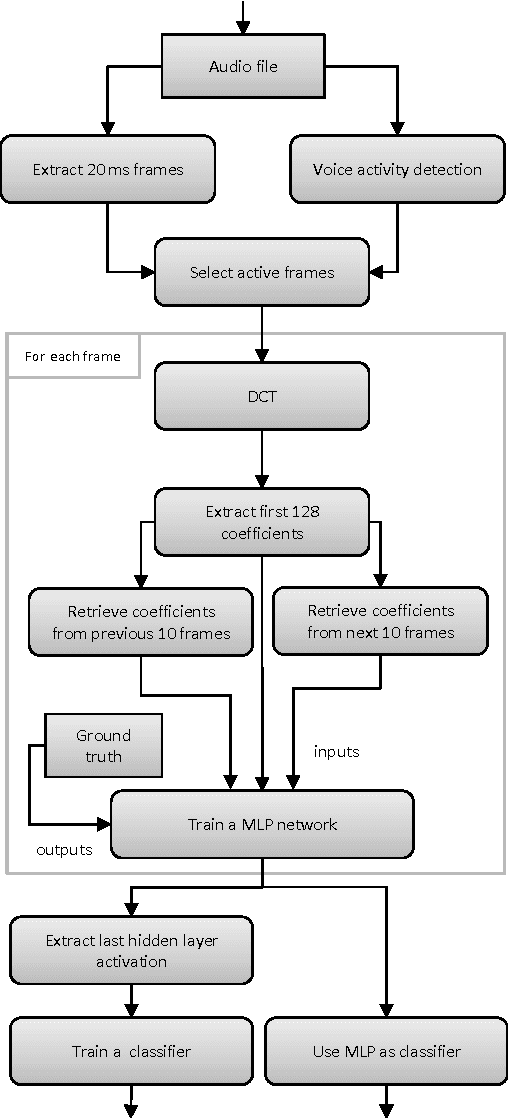
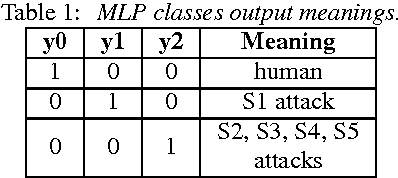
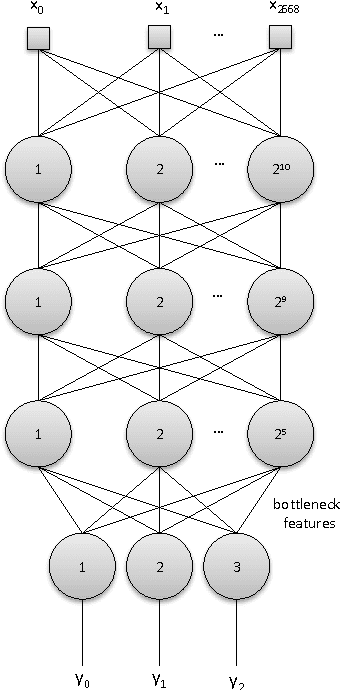
It is well known that speaker verification systems are subject to spoofing attacks. The Automatic Speaker Verification Spoofing and Countermeasures Challenge -- ASVSpoof2015 -- provides a standard spoofing database, containing attacks based on synthetic speech, along with a protocol for experiments. This paper describes CPqD's systems submitted to the ASVSpoof2015 Challenge, based on deep neural networks, working both as a classifier and as a feature extraction module for a GMM and a SVM classifier. Results show the validity of this approach, achieving less than 0.5\% EER for known attacks.