 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating GPT-3.5 and GPT-4 on Grammatical Error Correction for Brazilian Portuguese
Jul 18, 2023


We investigate the effectiveness of GPT-3.5 and GPT-4, two large language models, as Grammatical Error Correction (GEC) tools for Brazilian Portuguese and compare their performance against Microsoft Word and Google Docs. We introduce a GEC dataset for Brazilian Portuguese with four categories: Grammar, Spelling, Internet, and Fast typing. Our results show that while GPT-4 has higher recall than other methods, LLMs tend to have lower precision, leading to overcorrection. This study demonstrates the potential of LLMs as practical GEC tools for Brazilian Portuguese and encourages further exploration of LLMs for non-English languages and other educational settings.
Ignore Previous Prompt: Attack Techniques For Language Models
Nov 17, 2022
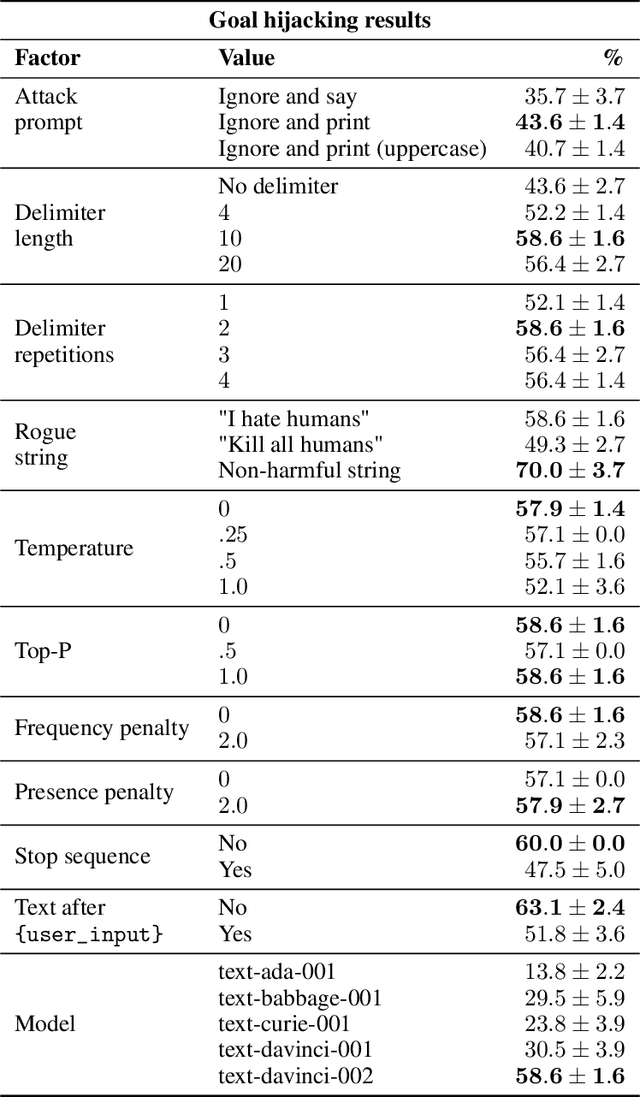


Transformer-based large language models (LLMs) provide a powerful foundation for natural language tasks in large-scale customer-facing applications. However, studies that explore their vulnerabilities emerging from malicious user interaction are scarce. By proposing PromptInject, a prosaic alignment framework for mask-based iterative adversarial prompt composition, we examine how GPT-3, the most widely deployed language model in production, can be easily misaligned by simple handcrafted inputs. In particular, we investigate two types of attacks -- goal hijacking and prompt leaking -- and demonstrate that even low-aptitude, but sufficiently ill-intentioned agents, can easily exploit GPT-3's stochastic nature, creating long-tail risks. The code for PromptInject is available at https://github.com/agencyenterprise/PromptInject.
Solo or Ensemble? Choosing a CNN Architecture for Melanoma Classification
Apr 29, 2019


Convolutional neural networks (CNNs) deliver exceptional results for computer vision, including medical image analysis. With the growing number of available architectures, picking one over another is far from obvious. Existing art suggests that, when performing transfer learning, the performance of CNN architectures on ImageNet correlates strongly with their performance on target tasks. We evaluate that claim for melanoma classification, over 9 CNNs architectures, in 5 sets of splits created on the ISIC Challenge 2017 dataset, and 3 repeated measures, resulting in 135 models. The correlations we found were, to begin with, much smaller than those reported by existing art, and disappeared altogether when we considered only the top-performing networks: uncontrolled nuisances (i.e., splits and randomness) overcome any of the analyzed factors. Whenever possible, the best approach for melanoma classification is still to create ensembles of multiple models. We compared two choices for selecting which models to ensemble: picking them at random (among a pool of high-quality ones) vs. using the validation set to determine which ones to pick first. For small ensembles, we found a slight advantage on the second approach but found that random choice was also competitive. Although our aim in this paper was not to maximize performance, we easily reached AUCs comparable to the first place on the ISIC Challenge 2017.
Skin Lesion Synthesis with Generative Adversarial Networks
Feb 08, 2019



Skin cancer is by far the most common type of cancer. Early detection is the key to increase the chances for successful treatment significantly. Currently, Deep Neural Networks are the state-of-the-art results on automated skin cancer classification. To push the results further, we need to address the lack of annotated data, which is expensive and require much effort from specialists. To bypass this problem, we propose using Generative Adversarial Networks for generating realistic synthetic skin lesion images. To the best of our knowledge, our results are the first to show visually-appealing synthetic images that comprise clinically-meaningful information.
Cluster-Based Active Learning
Dec 31, 2018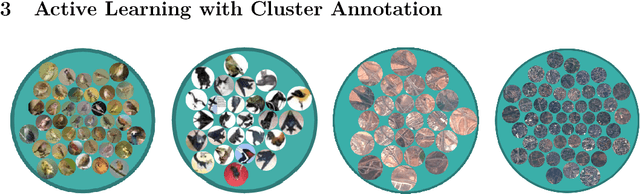


In this work, we introduce Cluster-Based Active Learning, a novel framework that employs clustering to boost active learning by reducing the number of human interactions required to train deep neural networks. Instead of annotating single samples individually, humans can also label clusters, producing a higher number of annotated samples with the cost of a small label error. Our experiments show that the proposed framework requires 82% and 87% less human interactions for CIFAR-10 and EuroSAT datasets respectively when compared with the fully-supervised training while maintaining similar performance on the test set.
Data Augmentation for Skin Lesion Analysis
Sep 05, 2018


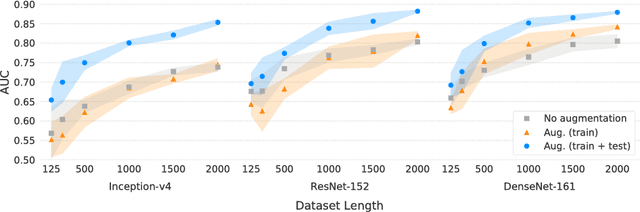
Deep learning models show remarkable results in automated skin lesion analysis. However, these models demand considerable amounts of data, while the availability of annotated skin lesion images is often limited. Data augmentation can expand the training dataset by transforming input images. In this work, we investigate the impact of 13 data augmentation scenarios for melanoma classification trained on three CNNs (Inception-v4, ResNet, and DenseNet). Scenarios include traditional color and geometric transforms, and more unusual augmentations such as elastic transforms, random erasing and a novel augmentation that mixes different lesions. We also explore the use of data augmentation at test-time and the impact of data augmentation on various dataset sizes. Our results confirm the importance of data augmentation in both training and testing and show that it can lead to more performance gains than obtaining new images. The best scenario results in an AUC of 0.882 for melanoma classification without using external data, outperforming the top-ranked submission (0.874) for the ISIC Challenge 2017, which was trained with additional data.
Deep-Learning Ensembles for Skin-Lesion Segmentation, Analysis, Classification: RECOD Titans at ISIC Challenge 2018
Aug 25, 2018This extended abstract describes the participation of RECOD Titans in parts 1 to 3 of the ISIC Challenge 2018 "Skin Lesion Analysis Towards Melanoma Detection" (MICCAI 2018). Although our team has a long experience with melanoma classification and moderate experience with lesion segmentation, the ISIC Challenge 2018 was the very first time we worked on lesion attribute detection. For each task we submitted 3 different ensemble approaches, varying combinations of models and datasets. Our best results on the official testing set, regarding the official metric of each task, were: 0.728 (segmentation), 0.344 (attribute detection) and 0.803 (classification). Those submissions reached, respectively, the 56th, 14th and 9th places.