 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Synthetically Generated Data with Semi-Supervised Learning for Small and Imbalanced Datasets
Mar 24, 2019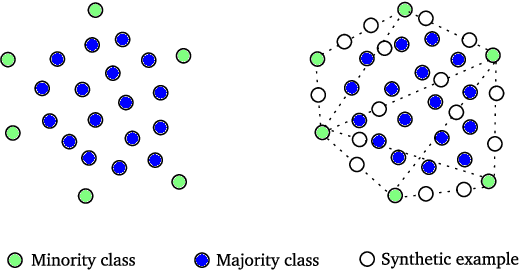
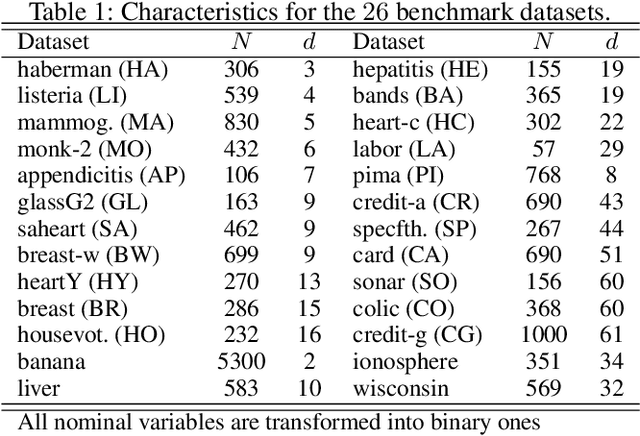
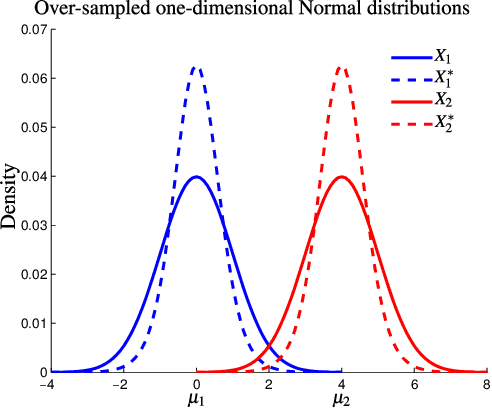
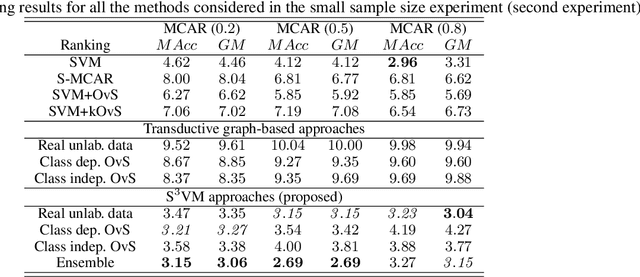
Data augmentation is rapidly gaining attention in machine learning. Synthetic data can be generated by simple transformations or through the data distribution. In the latter case, the main challenge is to estimate the label associated to new synthetic patterns. This paper studies the effect of generating synthetic data by convex combination of patterns and the use of these as unsupervised information in a semi-supervised learning framework with support vector machines, avoiding thus the need to label synthetic examples. We perform experiments on a total of 53 binary classification datasets. Our results show that this type of data over-sampling supports the well-known cluster assumption in semi-supervised learning, showing outstanding results for small high-dimensional datasets and imbalanced learning problems.