 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeRaDiff: Denoising Time Realignment of Diffusion Models
Jan 28, 2026Recent advances align diffusion models with human preferences to increase aesthetic appeal and mitigate artifacts and biases. Such methods aim to maximize a conditional output distribution aligned with higher rewards whilst not drifting far from a pretrained prior. This is commonly enforced by KL (Kullback Leibler) regularization. As such, a central issue still remains: how does one choose the right regularization strength? Too high of a strength leads to limited alignment and too low of a strength leads to "reward hacking". This renders the task of choosing the correct regularization strength highly non-trivial. Existing approaches sweep over this hyperparameter by aligning a pretrained model at multiple regularization strengths and then choose the best strength. Unfortunately, this is prohibitively expensive. We introduce DeRaDiff, a denoising time realignment procedure that, after aligning a pretrained model once, modulates the regularization strength during sampling to emulate models trained at other regularization strengths without any additional training or finetuning. Extending decoding-time realignment from language to diffusion models, DeRaDiff operates over iterative predictions of continuous latents by replacing the reverse step reference distribution by a geometric mixture of an aligned and reference posterior, thus giving rise to a closed form update under common schedulers and a single tunable parameter, lambda, for on the fly control. Our experiments show that across multiple text image alignment and image-quality metrics, our method consistently provides a strong approximation for models aligned entirely from scratch at different regularization strengths. Thus, our method yields an efficient way to search for the optimal strength, eliminating the need for expensive alignment sweeps and thereby substantially reducing computational costs.
Enhancing Semantic Fidelity in Text-to-Image Synthesis: Attention Regulation in Diffusion Models
Mar 11, 2024

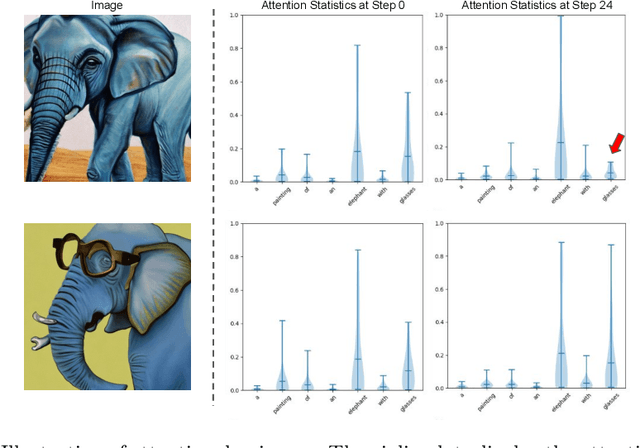

Recent advancements in diffusion models have notably improved the perceptual quality of generated images in text-to-image synthesis tasks. However, diffusion models often struggle to produce images that accurately reflect the intended semantics of the associated text prompts. We examine cross-attention layers in diffusion models and observe a propensity for these layers to disproportionately focus on certain tokens during the generation process, thereby undermining semantic fidelity. To address the issue of dominant attention, we introduce attention regulation, a computation-efficient on-the-fly optimization approach at inference time to align attention maps with the input text prompt. Notably, our method requires no additional training or fine-tuning and serves as a plug-in module on a model. Hence, the generation capacity of the original model is fully preserved. We compare our approach with alternative approaches across various datasets, evaluation metrics, and diffusion models. Experiment results show that our method consistently outperforms other baselines, yielding images that more faithfully reflect the desired concepts with reduced computation overhead. Code is available at https://github.com/YaNgZhAnG-V5/attention_regulation.