 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Labels Can Induce Good Representations
Paper and Code
Dec 23, 2020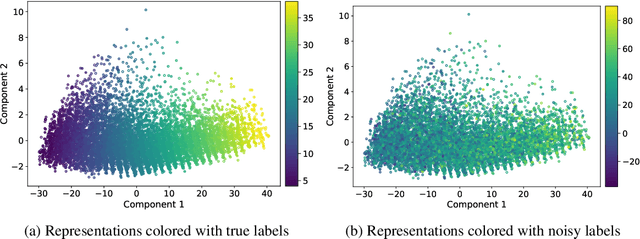

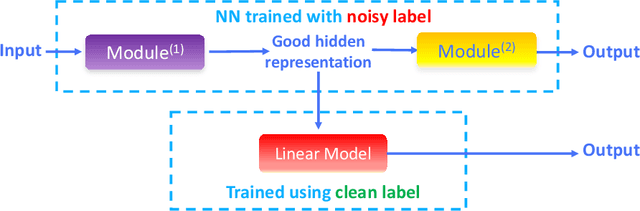
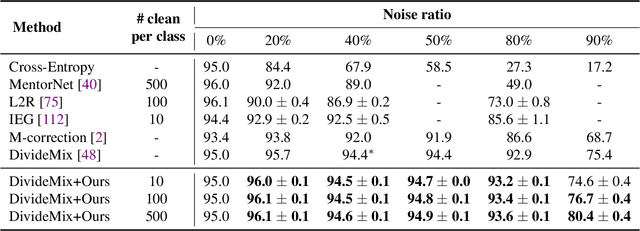
The current success of deep learning depends on large-scale labeled datasets. In practice, high-quality annotations are expensive to collect, but noisy annotations are more affordable. Previous works report mixed empirical results when training with noisy labels: neural networks can easily memorize random labels, but they can also generalize from noisy labels. To explain this puzzle, we study how architecture affects learning with noisy labels. We observe that if an architecture "suits" the task, training with noisy labels can induce useful hidden representations, even when the model generalizes poorly; i.e., the last few layers of the model are more negatively affected by noisy labels. This finding leads to a simple method to improve models trained on noisy labels: replacing the final dense layers with a linear model, whose weights are learned from a small set of clean data. We empirically validate our findings across three architectures (Convolutional Neural Networks, Graph Neural Networks, and Multi-Layer Perceptrons) and two domains (graph algorithmic tasks and image classification). Furthermore, we achieve state-of-the-art results on image classification benchmarks by combining our method with existing approaches on noisy label training.